
Package Summary
| Version | 0.0.0 |
| License | BSD |
| Build type | CATKIN |
| Use | RECOMMENDED |
Repository Summary
| Checkout URI | https://github.com/SMRT-AIST/fast_gicp.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2025-04-24 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Package Description
Additional Links
Maintainers
- k.koide
Authors
Note: New faster library is released
We released small_gicp that is twice as fast as fast_gicp and with minimum dependencies and clean interfaces.
fast_gicp
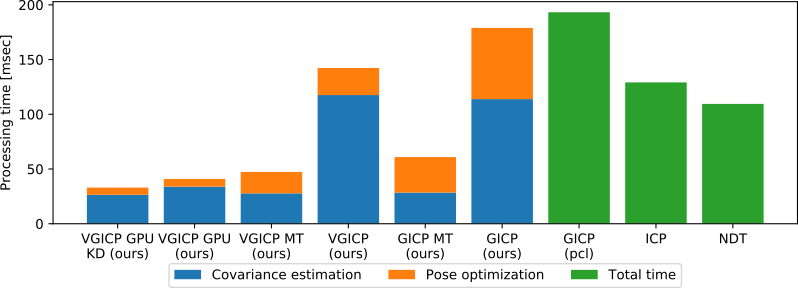
This package is a collection of GICP-based fast point cloud registration algorithms. It constains a multi-threaded GICP as well as multi-thread and GPU implementations of our voxelized GICP (VGICP) algorithm. All the implemented algorithms have the PCL registration interface so that they can be used as an inplace replacement for GICP in PCL.
- FastGICP: multi-threaded GICP algorithm (~40FPS)
- FastGICPSingleThread: GICP algorithm optimized for single-threading (~15FPS)
- FastVGICP: multi-threaded and voxelized GICP algorithm (~70FPS)
- FastVGICPCuda: CUDA-accelerated voxelized GICP algorithm (~120FPS)
- NDTCuda: CUDA-accelerated D2D NDT algorithm (~500FPS)
![]() on melodic & noetic
on melodic & noetic
Installation
Dependencies
We have tested this package on Ubuntu 18.04/20.04 and CUDA 11.1.
On macOS when using brew, you might have to set up your depenencies like this
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
CUDA
To enable the CUDA-powered implementations, set
``` cmake option to
```ON
```.
### ROS
```bash
cd ~/catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
Non-ROS
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8
Python bindings
cd fast_gicp
python3 setup.py install --user
Note: If you are on a catkin-enabled environment and the installation doesn’t work well, comment out
find_package(catkin)
in CMakeLists.txt and run the above installation command again.
```python import pygicp
target = # Nx3 numpy array source = # Mx3 numpy array
1. function interface
matrix = pygicp.align_points(target, source)
optional arguments
initial_guess : Initial guess of the relative pose (4x4 matrix)
method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
downsample_resolution : Downsampling resolution (used only if positive)
k_correspondences : Number of points used for covariance estimation
max_correspondence_distance : Maximum distance for corresponding point search
voxel_resolution : Resolution of voxel-based algorithms
neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
num_threads : Number of threads
2. class interface
you may want to downsample the input clouds before registration
target = pygicp.downsample(target, 0.25) source = pygicp.downsample(source, 0.25)
pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp.FastGICP() gicp.set_input_target(target) gicp.set_input_source(source) matrix = gicp.align()
optional
File truncated at 100 lines see the full file
Package Dependencies
| Deps | Name |
|---|---|
| ros_environment | |
| catkin | |
| ament_cmake |
System Dependencies
| Name |
|---|
| libpcl-all-dev |
| eigen |
Dependant Packages
| Name | Deps |
|---|---|
| lidar_situational_graphs |
Launch files
Messages
Services
Plugins
Recent questions tagged fast_gicp at Robotics Stack Exchange
Package Summary
| Version | 0.0.0 |
| License | BSD |
| Build type | CATKIN |
| Use | RECOMMENDED |
Repository Summary
| Checkout URI | https://github.com/SMRT-AIST/fast_gicp.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2025-04-24 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Package Description
Additional Links
Maintainers
- k.koide
Authors
Note: New faster library is released
We released small_gicp that is twice as fast as fast_gicp and with minimum dependencies and clean interfaces.
fast_gicp
This package is a collection of GICP-based fast point cloud registration algorithms. It constains a multi-threaded GICP as well as multi-thread and GPU implementations of our voxelized GICP (VGICP) algorithm. All the implemented algorithms have the PCL registration interface so that they can be used as an inplace replacement for GICP in PCL.
- FastGICP: multi-threaded GICP algorithm (~40FPS)
- FastGICPSingleThread: GICP algorithm optimized for single-threading (~15FPS)
- FastVGICP: multi-threaded and voxelized GICP algorithm (~70FPS)
- FastVGICPCuda: CUDA-accelerated voxelized GICP algorithm (~120FPS)
- NDTCuda: CUDA-accelerated D2D NDT algorithm (~500FPS)
![]() on melodic & noetic
on melodic & noetic
Installation
Dependencies
We have tested this package on Ubuntu 18.04/20.04 and CUDA 11.1.
On macOS when using brew, you might have to set up your depenencies like this
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
CUDA
To enable the CUDA-powered implementations, set
``` cmake option to
```ON
```.
### ROS
```bash
cd ~/catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
Non-ROS
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8
Python bindings
cd fast_gicp
python3 setup.py install --user
Note: If you are on a catkin-enabled environment and the installation doesn’t work well, comment out
find_package(catkin)
in CMakeLists.txt and run the above installation command again.
```python import pygicp
target = # Nx3 numpy array source = # Mx3 numpy array
1. function interface
matrix = pygicp.align_points(target, source)
optional arguments
initial_guess : Initial guess of the relative pose (4x4 matrix)
method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
downsample_resolution : Downsampling resolution (used only if positive)
k_correspondences : Number of points used for covariance estimation
max_correspondence_distance : Maximum distance for corresponding point search
voxel_resolution : Resolution of voxel-based algorithms
neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
num_threads : Number of threads
2. class interface
you may want to downsample the input clouds before registration
target = pygicp.downsample(target, 0.25) source = pygicp.downsample(source, 0.25)
pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp.FastGICP() gicp.set_input_target(target) gicp.set_input_source(source) matrix = gicp.align()
optional
File truncated at 100 lines see the full file
Package Dependencies
| Deps | Name |
|---|---|
| ros_environment | |
| catkin | |
| ament_cmake |
System Dependencies
| Name |
|---|
| libpcl-all-dev |
| eigen |
Dependant Packages
| Name | Deps |
|---|---|
| lidar_situational_graphs |
Launch files
Messages
Services
Plugins
Recent questions tagged fast_gicp at Robotics Stack Exchange
Package Summary
| Version | 0.0.0 |
| License | BSD |
| Build type | CATKIN |
| Use | RECOMMENDED |
Repository Summary
| Checkout URI | https://github.com/SMRT-AIST/fast_gicp.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2025-04-24 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Package Description
Additional Links
Maintainers
- k.koide
Authors
Note: New faster library is released
We released small_gicp that is twice as fast as fast_gicp and with minimum dependencies and clean interfaces.
fast_gicp
This package is a collection of GICP-based fast point cloud registration algorithms. It constains a multi-threaded GICP as well as multi-thread and GPU implementations of our voxelized GICP (VGICP) algorithm. All the implemented algorithms have the PCL registration interface so that they can be used as an inplace replacement for GICP in PCL.
- FastGICP: multi-threaded GICP algorithm (~40FPS)
- FastGICPSingleThread: GICP algorithm optimized for single-threading (~15FPS)
- FastVGICP: multi-threaded and voxelized GICP algorithm (~70FPS)
- FastVGICPCuda: CUDA-accelerated voxelized GICP algorithm (~120FPS)
- NDTCuda: CUDA-accelerated D2D NDT algorithm (~500FPS)
![]() on melodic & noetic
on melodic & noetic
Installation
Dependencies
We have tested this package on Ubuntu 18.04/20.04 and CUDA 11.1.
On macOS when using brew, you might have to set up your depenencies like this
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
CUDA
To enable the CUDA-powered implementations, set
``` cmake option to
```ON
```.
### ROS
```bash
cd ~/catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
Non-ROS
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8
Python bindings
cd fast_gicp
python3 setup.py install --user
Note: If you are on a catkin-enabled environment and the installation doesn’t work well, comment out
find_package(catkin)
in CMakeLists.txt and run the above installation command again.
```python import pygicp
target = # Nx3 numpy array source = # Mx3 numpy array
1. function interface
matrix = pygicp.align_points(target, source)
optional arguments
initial_guess : Initial guess of the relative pose (4x4 matrix)
method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
downsample_resolution : Downsampling resolution (used only if positive)
k_correspondences : Number of points used for covariance estimation
max_correspondence_distance : Maximum distance for corresponding point search
voxel_resolution : Resolution of voxel-based algorithms
neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
num_threads : Number of threads
2. class interface
you may want to downsample the input clouds before registration
target = pygicp.downsample(target, 0.25) source = pygicp.downsample(source, 0.25)
pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp.FastGICP() gicp.set_input_target(target) gicp.set_input_source(source) matrix = gicp.align()
optional
File truncated at 100 lines see the full file
Package Dependencies
| Deps | Name |
|---|---|
| ros_environment | |
| catkin | |
| ament_cmake |
System Dependencies
| Name |
|---|
| libpcl-all-dev |
| eigen |
Dependant Packages
| Name | Deps |
|---|---|
| lidar_situational_graphs |
Launch files
Messages
Services
Plugins
Recent questions tagged fast_gicp at Robotics Stack Exchange
Package Summary
| Version | 0.0.0 |
| License | BSD |
| Build type | CATKIN |
| Use | RECOMMENDED |
Repository Summary
| Checkout URI | https://github.com/SMRT-AIST/fast_gicp.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2025-04-24 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Package Description
Additional Links
Maintainers
- k.koide
Authors
Note: New faster library is released
We released small_gicp that is twice as fast as fast_gicp and with minimum dependencies and clean interfaces.
fast_gicp
This package is a collection of GICP-based fast point cloud registration algorithms. It constains a multi-threaded GICP as well as multi-thread and GPU implementations of our voxelized GICP (VGICP) algorithm. All the implemented algorithms have the PCL registration interface so that they can be used as an inplace replacement for GICP in PCL.
- FastGICP: multi-threaded GICP algorithm (~40FPS)
- FastGICPSingleThread: GICP algorithm optimized for single-threading (~15FPS)
- FastVGICP: multi-threaded and voxelized GICP algorithm (~70FPS)
- FastVGICPCuda: CUDA-accelerated voxelized GICP algorithm (~120FPS)
- NDTCuda: CUDA-accelerated D2D NDT algorithm (~500FPS)
![]() on melodic & noetic
on melodic & noetic
Installation
Dependencies
We have tested this package on Ubuntu 18.04/20.04 and CUDA 11.1.
On macOS when using brew, you might have to set up your depenencies like this
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
CUDA
To enable the CUDA-powered implementations, set
``` cmake option to
```ON
```.
### ROS
```bash
cd ~/catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
Non-ROS
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8
Python bindings
cd fast_gicp
python3 setup.py install --user
Note: If you are on a catkin-enabled environment and the installation doesn’t work well, comment out
find_package(catkin)
in CMakeLists.txt and run the above installation command again.
```python import pygicp
target = # Nx3 numpy array source = # Mx3 numpy array
1. function interface
matrix = pygicp.align_points(target, source)
optional arguments
initial_guess : Initial guess of the relative pose (4x4 matrix)
method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
downsample_resolution : Downsampling resolution (used only if positive)
k_correspondences : Number of points used for covariance estimation
max_correspondence_distance : Maximum distance for corresponding point search
voxel_resolution : Resolution of voxel-based algorithms
neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
num_threads : Number of threads
2. class interface
you may want to downsample the input clouds before registration
target = pygicp.downsample(target, 0.25) source = pygicp.downsample(source, 0.25)
pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp.FastGICP() gicp.set_input_target(target) gicp.set_input_source(source) matrix = gicp.align()
optional
File truncated at 100 lines see the full file
Package Dependencies
| Deps | Name |
|---|---|
| ros_environment | |
| catkin | |
| ament_cmake |
System Dependencies
| Name |
|---|
| libpcl-all-dev |
| eigen |
Dependant Packages
| Name | Deps |
|---|---|
| lidar_situational_graphs |
Launch files
Messages
Services
Plugins
Recent questions tagged fast_gicp at Robotics Stack Exchange
Package Summary
| Version | 0.0.0 |
| License | BSD |
| Build type | CATKIN |
| Use | RECOMMENDED |
Repository Summary
| Checkout URI | https://github.com/SMRT-AIST/fast_gicp.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2025-04-24 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Package Description
Additional Links
Maintainers
- k.koide
Authors
Note: New faster library is released
We released small_gicp that is twice as fast as fast_gicp and with minimum dependencies and clean interfaces.
fast_gicp
This package is a collection of GICP-based fast point cloud registration algorithms. It constains a multi-threaded GICP as well as multi-thread and GPU implementations of our voxelized GICP (VGICP) algorithm. All the implemented algorithms have the PCL registration interface so that they can be used as an inplace replacement for GICP in PCL.
- FastGICP: multi-threaded GICP algorithm (~40FPS)
- FastGICPSingleThread: GICP algorithm optimized for single-threading (~15FPS)
- FastVGICP: multi-threaded and voxelized GICP algorithm (~70FPS)
- FastVGICPCuda: CUDA-accelerated voxelized GICP algorithm (~120FPS)
- NDTCuda: CUDA-accelerated D2D NDT algorithm (~500FPS)
![]() on melodic & noetic
on melodic & noetic
Installation
Dependencies
We have tested this package on Ubuntu 18.04/20.04 and CUDA 11.1.
On macOS when using brew, you might have to set up your depenencies like this
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
CUDA
To enable the CUDA-powered implementations, set
``` cmake option to
```ON
```.
### ROS
```bash
cd ~/catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
Non-ROS
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8
Python bindings
cd fast_gicp
python3 setup.py install --user
Note: If you are on a catkin-enabled environment and the installation doesn’t work well, comment out
find_package(catkin)
in CMakeLists.txt and run the above installation command again.
```python import pygicp
target = # Nx3 numpy array source = # Mx3 numpy array
1. function interface
matrix = pygicp.align_points(target, source)
optional arguments
initial_guess : Initial guess of the relative pose (4x4 matrix)
method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
downsample_resolution : Downsampling resolution (used only if positive)
k_correspondences : Number of points used for covariance estimation
max_correspondence_distance : Maximum distance for corresponding point search
voxel_resolution : Resolution of voxel-based algorithms
neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
num_threads : Number of threads
2. class interface
you may want to downsample the input clouds before registration
target = pygicp.downsample(target, 0.25) source = pygicp.downsample(source, 0.25)
pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp.FastGICP() gicp.set_input_target(target) gicp.set_input_source(source) matrix = gicp.align()
optional
File truncated at 100 lines see the full file
Package Dependencies
| Deps | Name |
|---|---|
| ros_environment | |
| catkin | |
| ament_cmake |
System Dependencies
| Name |
|---|
| libpcl-all-dev |
| eigen |
Dependant Packages
| Name | Deps |
|---|---|
| lidar_situational_graphs |
Launch files
Messages
Services
Plugins
Recent questions tagged fast_gicp at Robotics Stack Exchange
Package Summary
| Version | 0.0.0 |
| License | BSD |
| Build type | CATKIN |
| Use | RECOMMENDED |
Repository Summary
| Checkout URI | https://github.com/SMRT-AIST/fast_gicp.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2025-04-24 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Package Description
Additional Links
Maintainers
- k.koide
Authors
Note: New faster library is released
We released small_gicp that is twice as fast as fast_gicp and with minimum dependencies and clean interfaces.
fast_gicp
This package is a collection of GICP-based fast point cloud registration algorithms. It constains a multi-threaded GICP as well as multi-thread and GPU implementations of our voxelized GICP (VGICP) algorithm. All the implemented algorithms have the PCL registration interface so that they can be used as an inplace replacement for GICP in PCL.
- FastGICP: multi-threaded GICP algorithm (~40FPS)
- FastGICPSingleThread: GICP algorithm optimized for single-threading (~15FPS)
- FastVGICP: multi-threaded and voxelized GICP algorithm (~70FPS)
- FastVGICPCuda: CUDA-accelerated voxelized GICP algorithm (~120FPS)
- NDTCuda: CUDA-accelerated D2D NDT algorithm (~500FPS)
![]() on melodic & noetic
on melodic & noetic
Installation
Dependencies
We have tested this package on Ubuntu 18.04/20.04 and CUDA 11.1.
On macOS when using brew, you might have to set up your depenencies like this
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
CUDA
To enable the CUDA-powered implementations, set
``` cmake option to
```ON
```.
### ROS
```bash
cd ~/catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
Non-ROS
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8
Python bindings
cd fast_gicp
python3 setup.py install --user
Note: If you are on a catkin-enabled environment and the installation doesn’t work well, comment out
find_package(catkin)
in CMakeLists.txt and run the above installation command again.
```python import pygicp
target = # Nx3 numpy array source = # Mx3 numpy array
1. function interface
matrix = pygicp.align_points(target, source)
optional arguments
initial_guess : Initial guess of the relative pose (4x4 matrix)
method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
downsample_resolution : Downsampling resolution (used only if positive)
k_correspondences : Number of points used for covariance estimation
max_correspondence_distance : Maximum distance for corresponding point search
voxel_resolution : Resolution of voxel-based algorithms
neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
num_threads : Number of threads
2. class interface
you may want to downsample the input clouds before registration
target = pygicp.downsample(target, 0.25) source = pygicp.downsample(source, 0.25)
pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp.FastGICP() gicp.set_input_target(target) gicp.set_input_source(source) matrix = gicp.align()
optional
File truncated at 100 lines see the full file
Package Dependencies
| Deps | Name |
|---|---|
| ros_environment | |
| catkin | |
| ament_cmake |
System Dependencies
| Name |
|---|
| libpcl-all-dev |
| eigen |
Dependant Packages
| Name | Deps |
|---|---|
| lidar_situational_graphs |
Launch files
Messages
Services
Plugins
Recent questions tagged fast_gicp at Robotics Stack Exchange
Package Summary
| Version | 0.0.0 |
| License | BSD |
| Build type | CATKIN |
| Use | RECOMMENDED |
Repository Summary
| Checkout URI | https://github.com/SMRT-AIST/fast_gicp.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2025-04-24 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Package Description
Additional Links
Maintainers
- k.koide
Authors
Note: New faster library is released
We released small_gicp that is twice as fast as fast_gicp and with minimum dependencies and clean interfaces.
fast_gicp
This package is a collection of GICP-based fast point cloud registration algorithms. It constains a multi-threaded GICP as well as multi-thread and GPU implementations of our voxelized GICP (VGICP) algorithm. All the implemented algorithms have the PCL registration interface so that they can be used as an inplace replacement for GICP in PCL.
- FastGICP: multi-threaded GICP algorithm (~40FPS)
- FastGICPSingleThread: GICP algorithm optimized for single-threading (~15FPS)
- FastVGICP: multi-threaded and voxelized GICP algorithm (~70FPS)
- FastVGICPCuda: CUDA-accelerated voxelized GICP algorithm (~120FPS)
- NDTCuda: CUDA-accelerated D2D NDT algorithm (~500FPS)
![]() on melodic & noetic
on melodic & noetic
Installation
Dependencies
We have tested this package on Ubuntu 18.04/20.04 and CUDA 11.1.
On macOS when using brew, you might have to set up your depenencies like this
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
CUDA
To enable the CUDA-powered implementations, set
``` cmake option to
```ON
```.
### ROS
```bash
cd ~/catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
Non-ROS
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8
Python bindings
cd fast_gicp
python3 setup.py install --user
Note: If you are on a catkin-enabled environment and the installation doesn’t work well, comment out
find_package(catkin)
in CMakeLists.txt and run the above installation command again.
```python import pygicp
target = # Nx3 numpy array source = # Mx3 numpy array
1. function interface
matrix = pygicp.align_points(target, source)
optional arguments
initial_guess : Initial guess of the relative pose (4x4 matrix)
method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
downsample_resolution : Downsampling resolution (used only if positive)
k_correspondences : Number of points used for covariance estimation
max_correspondence_distance : Maximum distance for corresponding point search
voxel_resolution : Resolution of voxel-based algorithms
neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
num_threads : Number of threads
2. class interface
you may want to downsample the input clouds before registration
target = pygicp.downsample(target, 0.25) source = pygicp.downsample(source, 0.25)
pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp.FastGICP() gicp.set_input_target(target) gicp.set_input_source(source) matrix = gicp.align()
optional
File truncated at 100 lines see the full file
Package Dependencies
| Deps | Name |
|---|---|
| ros_environment | |
| catkin | |
| ament_cmake |
System Dependencies
| Name |
|---|
| libpcl-all-dev |
| eigen |
Dependant Packages
| Name | Deps |
|---|---|
| lidar_situational_graphs |
Launch files
Messages
Services
Plugins
Recent questions tagged fast_gicp at Robotics Stack Exchange
Package Summary
| Version | 0.0.0 |
| License | BSD |
| Build type | CATKIN |
| Use | RECOMMENDED |
Repository Summary
| Checkout URI | https://github.com/SMRT-AIST/fast_gicp.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2025-04-24 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Package Description
Additional Links
Maintainers
- k.koide
Authors
Note: New faster library is released
We released small_gicp that is twice as fast as fast_gicp and with minimum dependencies and clean interfaces.
fast_gicp
This package is a collection of GICP-based fast point cloud registration algorithms. It constains a multi-threaded GICP as well as multi-thread and GPU implementations of our voxelized GICP (VGICP) algorithm. All the implemented algorithms have the PCL registration interface so that they can be used as an inplace replacement for GICP in PCL.
- FastGICP: multi-threaded GICP algorithm (~40FPS)
- FastGICPSingleThread: GICP algorithm optimized for single-threading (~15FPS)
- FastVGICP: multi-threaded and voxelized GICP algorithm (~70FPS)
- FastVGICPCuda: CUDA-accelerated voxelized GICP algorithm (~120FPS)
- NDTCuda: CUDA-accelerated D2D NDT algorithm (~500FPS)
![]() on melodic & noetic
on melodic & noetic
Installation
Dependencies
We have tested this package on Ubuntu 18.04/20.04 and CUDA 11.1.
On macOS when using brew, you might have to set up your depenencies like this
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
CUDA
To enable the CUDA-powered implementations, set
``` cmake option to
```ON
```.
### ROS
```bash
cd ~/catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
Non-ROS
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8
Python bindings
cd fast_gicp
python3 setup.py install --user
Note: If you are on a catkin-enabled environment and the installation doesn’t work well, comment out
find_package(catkin)
in CMakeLists.txt and run the above installation command again.
```python import pygicp
target = # Nx3 numpy array source = # Mx3 numpy array
1. function interface
matrix = pygicp.align_points(target, source)
optional arguments
initial_guess : Initial guess of the relative pose (4x4 matrix)
method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
downsample_resolution : Downsampling resolution (used only if positive)
k_correspondences : Number of points used for covariance estimation
max_correspondence_distance : Maximum distance for corresponding point search
voxel_resolution : Resolution of voxel-based algorithms
neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
num_threads : Number of threads
2. class interface
you may want to downsample the input clouds before registration
target = pygicp.downsample(target, 0.25) source = pygicp.downsample(source, 0.25)
pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp.FastGICP() gicp.set_input_target(target) gicp.set_input_source(source) matrix = gicp.align()
optional
File truncated at 100 lines see the full file
Package Dependencies
| Deps | Name |
|---|---|
| ros_environment | |
| catkin | |
| ament_cmake |
System Dependencies
| Name |
|---|
| libpcl-all-dev |
| eigen |
Dependant Packages
| Name | Deps |
|---|---|
| lidar_situational_graphs |
Launch files
Messages
Services
Plugins
Recent questions tagged fast_gicp at Robotics Stack Exchange
Package Summary
| Version | 0.0.0 |
| License | BSD |
| Build type | CATKIN |
| Use | RECOMMENDED |
Repository Summary
| Checkout URI | https://github.com/SMRT-AIST/fast_gicp.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2025-04-24 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Package Description
Additional Links
Maintainers
- k.koide
Authors
Note: New faster library is released
We released small_gicp that is twice as fast as fast_gicp and with minimum dependencies and clean interfaces.
fast_gicp
This package is a collection of GICP-based fast point cloud registration algorithms. It constains a multi-threaded GICP as well as multi-thread and GPU implementations of our voxelized GICP (VGICP) algorithm. All the implemented algorithms have the PCL registration interface so that they can be used as an inplace replacement for GICP in PCL.
- FastGICP: multi-threaded GICP algorithm (~40FPS)
- FastGICPSingleThread: GICP algorithm optimized for single-threading (~15FPS)
- FastVGICP: multi-threaded and voxelized GICP algorithm (~70FPS)
- FastVGICPCuda: CUDA-accelerated voxelized GICP algorithm (~120FPS)
- NDTCuda: CUDA-accelerated D2D NDT algorithm (~500FPS)
![]() on melodic & noetic
on melodic & noetic
Installation
Dependencies
We have tested this package on Ubuntu 18.04/20.04 and CUDA 11.1.
On macOS when using brew, you might have to set up your depenencies like this
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
CUDA
To enable the CUDA-powered implementations, set
``` cmake option to
```ON
```.
### ROS
```bash
cd ~/catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
Non-ROS
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8
Python bindings
cd fast_gicp
python3 setup.py install --user
Note: If you are on a catkin-enabled environment and the installation doesn’t work well, comment out
find_package(catkin)
in CMakeLists.txt and run the above installation command again.
```python import pygicp
target = # Nx3 numpy array source = # Mx3 numpy array
1. function interface
matrix = pygicp.align_points(target, source)
optional arguments
initial_guess : Initial guess of the relative pose (4x4 matrix)
method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
downsample_resolution : Downsampling resolution (used only if positive)
k_correspondences : Number of points used for covariance estimation
max_correspondence_distance : Maximum distance for corresponding point search
voxel_resolution : Resolution of voxel-based algorithms
neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
num_threads : Number of threads
2. class interface
you may want to downsample the input clouds before registration
target = pygicp.downsample(target, 0.25) source = pygicp.downsample(source, 0.25)
pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp.FastGICP() gicp.set_input_target(target) gicp.set_input_source(source) matrix = gicp.align()
optional
File truncated at 100 lines see the full file
Package Dependencies
| Deps | Name |
|---|---|
| ros_environment | |
| catkin | |
| ament_cmake |
System Dependencies
| Name |
|---|
| libpcl-all-dev |
| eigen |
Dependant Packages
| Name | Deps |
|---|---|
| lidar_situational_graphs |
Launch files
Messages
Services
Plugins
Recent questions tagged fast_gicp at Robotics Stack Exchange
Package Summary
| Version | 0.0.0 |
| License | BSD |
| Build type | CATKIN |
| Use | RECOMMENDED |
Repository Summary
| Checkout URI | https://github.com/SMRT-AIST/fast_gicp.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2025-04-24 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Package Description
Additional Links
Maintainers
- k.koide
Authors
Note: New faster library is released
We released small_gicp that is twice as fast as fast_gicp and with minimum dependencies and clean interfaces.
fast_gicp
This package is a collection of GICP-based fast point cloud registration algorithms. It constains a multi-threaded GICP as well as multi-thread and GPU implementations of our voxelized GICP (VGICP) algorithm. All the implemented algorithms have the PCL registration interface so that they can be used as an inplace replacement for GICP in PCL.
- FastGICP: multi-threaded GICP algorithm (~40FPS)
- FastGICPSingleThread: GICP algorithm optimized for single-threading (~15FPS)
- FastVGICP: multi-threaded and voxelized GICP algorithm (~70FPS)
- FastVGICPCuda: CUDA-accelerated voxelized GICP algorithm (~120FPS)
- NDTCuda: CUDA-accelerated D2D NDT algorithm (~500FPS)
![]() on melodic & noetic
on melodic & noetic
Installation
Dependencies
We have tested this package on Ubuntu 18.04/20.04 and CUDA 11.1.
On macOS when using brew, you might have to set up your depenencies like this
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
CUDA
To enable the CUDA-powered implementations, set
``` cmake option to
```ON
```.
### ROS
```bash
cd ~/catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
Non-ROS
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8
Python bindings
cd fast_gicp
python3 setup.py install --user
Note: If you are on a catkin-enabled environment and the installation doesn’t work well, comment out
find_package(catkin)
in CMakeLists.txt and run the above installation command again.
```python import pygicp
target = # Nx3 numpy array source = # Mx3 numpy array
1. function interface
matrix = pygicp.align_points(target, source)
optional arguments
initial_guess : Initial guess of the relative pose (4x4 matrix)
method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
downsample_resolution : Downsampling resolution (used only if positive)
k_correspondences : Number of points used for covariance estimation
max_correspondence_distance : Maximum distance for corresponding point search
voxel_resolution : Resolution of voxel-based algorithms
neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
num_threads : Number of threads
2. class interface
you may want to downsample the input clouds before registration
target = pygicp.downsample(target, 0.25) source = pygicp.downsample(source, 0.25)
pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp.FastGICP() gicp.set_input_target(target) gicp.set_input_source(source) matrix = gicp.align()
optional
File truncated at 100 lines see the full file
Package Dependencies
| Deps | Name |
|---|---|
| ros_environment | |
| catkin | |
| ament_cmake |
System Dependencies
| Name |
|---|
| libpcl-all-dev |
| eigen |
Dependant Packages
| Name | Deps |
|---|---|
| lidar_situational_graphs |
Launch files
Messages
Services
Plugins
Recent questions tagged fast_gicp at Robotics Stack Exchange
Package Summary
| Version | 0.0.0 |
| License | BSD |
| Build type | CATKIN |
| Use | RECOMMENDED |
Repository Summary
| Checkout URI | https://github.com/SMRT-AIST/fast_gicp.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2025-04-24 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Package Description
Additional Links
Maintainers
- k.koide
Authors
Note: New faster library is released
We released small_gicp that is twice as fast as fast_gicp and with minimum dependencies and clean interfaces.
fast_gicp
This package is a collection of GICP-based fast point cloud registration algorithms. It constains a multi-threaded GICP as well as multi-thread and GPU implementations of our voxelized GICP (VGICP) algorithm. All the implemented algorithms have the PCL registration interface so that they can be used as an inplace replacement for GICP in PCL.
- FastGICP: multi-threaded GICP algorithm (~40FPS)
- FastGICPSingleThread: GICP algorithm optimized for single-threading (~15FPS)
- FastVGICP: multi-threaded and voxelized GICP algorithm (~70FPS)
- FastVGICPCuda: CUDA-accelerated voxelized GICP algorithm (~120FPS)
- NDTCuda: CUDA-accelerated D2D NDT algorithm (~500FPS)
![]() on melodic & noetic
on melodic & noetic
Installation
Dependencies
We have tested this package on Ubuntu 18.04/20.04 and CUDA 11.1.
On macOS when using brew, you might have to set up your depenencies like this
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
CUDA
To enable the CUDA-powered implementations, set
``` cmake option to
```ON
```.
### ROS
```bash
cd ~/catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
Non-ROS
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8
Python bindings
cd fast_gicp
python3 setup.py install --user
Note: If you are on a catkin-enabled environment and the installation doesn’t work well, comment out
find_package(catkin)
in CMakeLists.txt and run the above installation command again.
```python import pygicp
target = # Nx3 numpy array source = # Mx3 numpy array
1. function interface
matrix = pygicp.align_points(target, source)
optional arguments
initial_guess : Initial guess of the relative pose (4x4 matrix)
method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
downsample_resolution : Downsampling resolution (used only if positive)
k_correspondences : Number of points used for covariance estimation
max_correspondence_distance : Maximum distance for corresponding point search
voxel_resolution : Resolution of voxel-based algorithms
neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
num_threads : Number of threads
2. class interface
you may want to downsample the input clouds before registration
target = pygicp.downsample(target, 0.25) source = pygicp.downsample(source, 0.25)
pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp.FastGICP() gicp.set_input_target(target) gicp.set_input_source(source) matrix = gicp.align()
optional
File truncated at 100 lines see the full file
Package Dependencies
| Deps | Name |
|---|---|
| ros_environment | |
| catkin | |
| ament_cmake |
System Dependencies
| Name |
|---|
| libpcl-all-dev |
| eigen |
Dependant Packages
| Name | Deps |
|---|---|
| lidar_situational_graphs |
Launch files
Messages
Services
Plugins
Recent questions tagged fast_gicp at Robotics Stack Exchange
Package Summary
| Version | 0.0.0 |
| License | BSD |
| Build type | CATKIN |
| Use | RECOMMENDED |
Repository Summary
| Checkout URI | https://github.com/SMRT-AIST/fast_gicp.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2025-04-24 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Package Description
Additional Links
Maintainers
- k.koide
Authors
Note: New faster library is released
We released small_gicp that is twice as fast as fast_gicp and with minimum dependencies and clean interfaces.
fast_gicp
This package is a collection of GICP-based fast point cloud registration algorithms. It constains a multi-threaded GICP as well as multi-thread and GPU implementations of our voxelized GICP (VGICP) algorithm. All the implemented algorithms have the PCL registration interface so that they can be used as an inplace replacement for GICP in PCL.
- FastGICP: multi-threaded GICP algorithm (~40FPS)
- FastGICPSingleThread: GICP algorithm optimized for single-threading (~15FPS)
- FastVGICP: multi-threaded and voxelized GICP algorithm (~70FPS)
- FastVGICPCuda: CUDA-accelerated voxelized GICP algorithm (~120FPS)
- NDTCuda: CUDA-accelerated D2D NDT algorithm (~500FPS)
![]() on melodic & noetic
on melodic & noetic
Installation
Dependencies
We have tested this package on Ubuntu 18.04/20.04 and CUDA 11.1.
On macOS when using brew, you might have to set up your depenencies like this
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
CUDA
To enable the CUDA-powered implementations, set
``` cmake option to
```ON
```.
### ROS
```bash
cd ~/catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
Non-ROS
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8
Python bindings
cd fast_gicp
python3 setup.py install --user
Note: If you are on a catkin-enabled environment and the installation doesn’t work well, comment out
find_package(catkin)
in CMakeLists.txt and run the above installation command again.
```python import pygicp
target = # Nx3 numpy array source = # Mx3 numpy array
1. function interface
matrix = pygicp.align_points(target, source)
optional arguments
initial_guess : Initial guess of the relative pose (4x4 matrix)
method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
downsample_resolution : Downsampling resolution (used only if positive)
k_correspondences : Number of points used for covariance estimation
max_correspondence_distance : Maximum distance for corresponding point search
voxel_resolution : Resolution of voxel-based algorithms
neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
num_threads : Number of threads
2. class interface
you may want to downsample the input clouds before registration
target = pygicp.downsample(target, 0.25) source = pygicp.downsample(source, 0.25)
pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp.FastGICP() gicp.set_input_target(target) gicp.set_input_source(source) matrix = gicp.align()
optional
File truncated at 100 lines see the full file
Package Dependencies
| Deps | Name |
|---|---|
| ros_environment | |
| catkin | |
| ament_cmake |
System Dependencies
| Name |
|---|
| libpcl-all-dev |
| eigen |
Dependant Packages
| Name | Deps |
|---|---|
| lidar_situational_graphs |
Launch files
Messages
Services
Plugins
Recent questions tagged fast_gicp at Robotics Stack Exchange
Package Summary
| Version | 0.0.0 |
| License | BSD |
| Build type | CATKIN |
| Use | RECOMMENDED |
Repository Summary
| Checkout URI | https://github.com/SMRT-AIST/fast_gicp.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2025-04-24 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Package Description
Additional Links
Maintainers
- k.koide
Authors
Note: New faster library is released
We released small_gicp that is twice as fast as fast_gicp and with minimum dependencies and clean interfaces.
fast_gicp
This package is a collection of GICP-based fast point cloud registration algorithms. It constains a multi-threaded GICP as well as multi-thread and GPU implementations of our voxelized GICP (VGICP) algorithm. All the implemented algorithms have the PCL registration interface so that they can be used as an inplace replacement for GICP in PCL.
- FastGICP: multi-threaded GICP algorithm (~40FPS)
- FastGICPSingleThread: GICP algorithm optimized for single-threading (~15FPS)
- FastVGICP: multi-threaded and voxelized GICP algorithm (~70FPS)
- FastVGICPCuda: CUDA-accelerated voxelized GICP algorithm (~120FPS)
- NDTCuda: CUDA-accelerated D2D NDT algorithm (~500FPS)
![]() on melodic & noetic
on melodic & noetic
Installation
Dependencies
We have tested this package on Ubuntu 18.04/20.04 and CUDA 11.1.
On macOS when using brew, you might have to set up your depenencies like this
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
CUDA
To enable the CUDA-powered implementations, set
``` cmake option to
```ON
```.
### ROS
```bash
cd ~/catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
Non-ROS
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8
Python bindings
cd fast_gicp
python3 setup.py install --user
Note: If you are on a catkin-enabled environment and the installation doesn’t work well, comment out
find_package(catkin)
in CMakeLists.txt and run the above installation command again.
```python import pygicp
target = # Nx3 numpy array source = # Mx3 numpy array
1. function interface
matrix = pygicp.align_points(target, source)
optional arguments
initial_guess : Initial guess of the relative pose (4x4 matrix)
method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
downsample_resolution : Downsampling resolution (used only if positive)
k_correspondences : Number of points used for covariance estimation
max_correspondence_distance : Maximum distance for corresponding point search
voxel_resolution : Resolution of voxel-based algorithms
neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
num_threads : Number of threads
2. class interface
you may want to downsample the input clouds before registration
target = pygicp.downsample(target, 0.25) source = pygicp.downsample(source, 0.25)
pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp.FastGICP() gicp.set_input_target(target) gicp.set_input_source(source) matrix = gicp.align()
optional
File truncated at 100 lines see the full file
Package Dependencies
| Deps | Name |
|---|---|
| ros_environment | |
| catkin | |
| ament_cmake |
System Dependencies
| Name |
|---|
| libpcl-all-dev |
| eigen |
Dependant Packages
| Name | Deps |
|---|---|
| lidar_situational_graphs |
Launch files
Messages
Services
Plugins
Recent questions tagged fast_gicp at Robotics Stack Exchange
Package Summary
| Version | 0.0.0 |
| License | BSD |
| Build type | CATKIN |
| Use | RECOMMENDED |
Repository Summary
| Checkout URI | https://github.com/SMRT-AIST/fast_gicp.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2025-04-24 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Package Description
Additional Links
Maintainers
- k.koide
Authors
Note: New faster library is released
We released small_gicp that is twice as fast as fast_gicp and with minimum dependencies and clean interfaces.
fast_gicp
This package is a collection of GICP-based fast point cloud registration algorithms. It constains a multi-threaded GICP as well as multi-thread and GPU implementations of our voxelized GICP (VGICP) algorithm. All the implemented algorithms have the PCL registration interface so that they can be used as an inplace replacement for GICP in PCL.
- FastGICP: multi-threaded GICP algorithm (~40FPS)
- FastGICPSingleThread: GICP algorithm optimized for single-threading (~15FPS)
- FastVGICP: multi-threaded and voxelized GICP algorithm (~70FPS)
- FastVGICPCuda: CUDA-accelerated voxelized GICP algorithm (~120FPS)
- NDTCuda: CUDA-accelerated D2D NDT algorithm (~500FPS)
![]() on melodic & noetic
on melodic & noetic
Installation
Dependencies
We have tested this package on Ubuntu 18.04/20.04 and CUDA 11.1.
On macOS when using brew, you might have to set up your depenencies like this
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
CUDA
To enable the CUDA-powered implementations, set
``` cmake option to
```ON
```.
### ROS
```bash
cd ~/catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
Non-ROS
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8
Python bindings
cd fast_gicp
python3 setup.py install --user
Note: If you are on a catkin-enabled environment and the installation doesn’t work well, comment out
find_package(catkin)
in CMakeLists.txt and run the above installation command again.
```python import pygicp
target = # Nx3 numpy array source = # Mx3 numpy array
1. function interface
matrix = pygicp.align_points(target, source)
optional arguments
initial_guess : Initial guess of the relative pose (4x4 matrix)
method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
downsample_resolution : Downsampling resolution (used only if positive)
k_correspondences : Number of points used for covariance estimation
max_correspondence_distance : Maximum distance for corresponding point search
voxel_resolution : Resolution of voxel-based algorithms
neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
num_threads : Number of threads
2. class interface
you may want to downsample the input clouds before registration
target = pygicp.downsample(target, 0.25) source = pygicp.downsample(source, 0.25)
pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp.FastGICP() gicp.set_input_target(target) gicp.set_input_source(source) matrix = gicp.align()
optional
File truncated at 100 lines see the full file
Package Dependencies
| Deps | Name |
|---|---|
| ros_environment | |
| catkin | |
| ament_cmake |
System Dependencies
| Name |
|---|
| libpcl-all-dev |
| eigen |
Dependant Packages
| Name | Deps |
|---|---|
| lidar_situational_graphs |
Launch files
Messages
Services
Plugins
Recent questions tagged fast_gicp at Robotics Stack Exchange
Package Summary
| Version | 0.0.0 |
| License | BSD |
| Build type | CATKIN |
| Use | RECOMMENDED |
Repository Summary
| Checkout URI | https://github.com/SMRT-AIST/fast_gicp.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2025-04-24 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Package Description
Additional Links
Maintainers
- k.koide
Authors
Note: New faster library is released
We released small_gicp that is twice as fast as fast_gicp and with minimum dependencies and clean interfaces.
fast_gicp
This package is a collection of GICP-based fast point cloud registration algorithms. It constains a multi-threaded GICP as well as multi-thread and GPU implementations of our voxelized GICP (VGICP) algorithm. All the implemented algorithms have the PCL registration interface so that they can be used as an inplace replacement for GICP in PCL.
- FastGICP: multi-threaded GICP algorithm (~40FPS)
- FastGICPSingleThread: GICP algorithm optimized for single-threading (~15FPS)
- FastVGICP: multi-threaded and voxelized GICP algorithm (~70FPS)
- FastVGICPCuda: CUDA-accelerated voxelized GICP algorithm (~120FPS)
- NDTCuda: CUDA-accelerated D2D NDT algorithm (~500FPS)
![]() on melodic & noetic
on melodic & noetic
Installation
Dependencies
We have tested this package on Ubuntu 18.04/20.04 and CUDA 11.1.
On macOS when using brew, you might have to set up your depenencies like this
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
CUDA
To enable the CUDA-powered implementations, set
``` cmake option to
```ON
```.
### ROS
```bash
cd ~/catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
Non-ROS
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8
Python bindings
cd fast_gicp
python3 setup.py install --user
Note: If you are on a catkin-enabled environment and the installation doesn’t work well, comment out
find_package(catkin)
in CMakeLists.txt and run the above installation command again.
```python import pygicp
target = # Nx3 numpy array source = # Mx3 numpy array
1. function interface
matrix = pygicp.align_points(target, source)
optional arguments
initial_guess : Initial guess of the relative pose (4x4 matrix)
method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
downsample_resolution : Downsampling resolution (used only if positive)
k_correspondences : Number of points used for covariance estimation
max_correspondence_distance : Maximum distance for corresponding point search
voxel_resolution : Resolution of voxel-based algorithms
neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
num_threads : Number of threads
2. class interface
you may want to downsample the input clouds before registration
target = pygicp.downsample(target, 0.25) source = pygicp.downsample(source, 0.25)
pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp.FastGICP() gicp.set_input_target(target) gicp.set_input_source(source) matrix = gicp.align()
optional
File truncated at 100 lines see the full file
Package Dependencies
| Deps | Name |
|---|---|
| ros_environment | |
| catkin | |
| ament_cmake |
System Dependencies
| Name |
|---|
| libpcl-all-dev |
| eigen |
Dependant Packages
| Name | Deps |
|---|---|
| lidar_situational_graphs |
Launch files
Messages
Services
Plugins
Recent questions tagged fast_gicp at Robotics Stack Exchange
Package Summary
| Version | 0.0.0 |
| License | BSD |
| Build type | CATKIN |
| Use | RECOMMENDED |
Repository Summary
| Checkout URI | https://github.com/SMRT-AIST/fast_gicp.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2025-04-24 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Package Description
Additional Links
Maintainers
- k.koide
Authors
Note: New faster library is released
We released small_gicp that is twice as fast as fast_gicp and with minimum dependencies and clean interfaces.
fast_gicp
This package is a collection of GICP-based fast point cloud registration algorithms. It constains a multi-threaded GICP as well as multi-thread and GPU implementations of our voxelized GICP (VGICP) algorithm. All the implemented algorithms have the PCL registration interface so that they can be used as an inplace replacement for GICP in PCL.
- FastGICP: multi-threaded GICP algorithm (~40FPS)
- FastGICPSingleThread: GICP algorithm optimized for single-threading (~15FPS)
- FastVGICP: multi-threaded and voxelized GICP algorithm (~70FPS)
- FastVGICPCuda: CUDA-accelerated voxelized GICP algorithm (~120FPS)
- NDTCuda: CUDA-accelerated D2D NDT algorithm (~500FPS)
![]() on melodic & noetic
on melodic & noetic
Installation
Dependencies
We have tested this package on Ubuntu 18.04/20.04 and CUDA 11.1.
On macOS when using brew, you might have to set up your depenencies like this
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
CUDA
To enable the CUDA-powered implementations, set
``` cmake option to
```ON
```.
### ROS
```bash
cd ~/catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
Non-ROS
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8
Python bindings
cd fast_gicp
python3 setup.py install --user
Note: If you are on a catkin-enabled environment and the installation doesn’t work well, comment out
find_package(catkin)
in CMakeLists.txt and run the above installation command again.
```python import pygicp
target = # Nx3 numpy array source = # Mx3 numpy array
1. function interface
matrix = pygicp.align_points(target, source)
optional arguments
initial_guess : Initial guess of the relative pose (4x4 matrix)
method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
downsample_resolution : Downsampling resolution (used only if positive)
k_correspondences : Number of points used for covariance estimation
max_correspondence_distance : Maximum distance for corresponding point search
voxel_resolution : Resolution of voxel-based algorithms
neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
num_threads : Number of threads
2. class interface
you may want to downsample the input clouds before registration
target = pygicp.downsample(target, 0.25) source = pygicp.downsample(source, 0.25)
pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp.FastGICP() gicp.set_input_target(target) gicp.set_input_source(source) matrix = gicp.align()
optional
File truncated at 100 lines see the full file
Package Dependencies
| Deps | Name |
|---|---|
| ros_environment | |
| catkin | |
| ament_cmake |
System Dependencies
| Name |
|---|
| libpcl-all-dev |
| eigen |
Dependant Packages
| Name | Deps |
|---|---|
| lidar_situational_graphs |
Launch files
Messages
Services
Plugins
Recent questions tagged fast_gicp at Robotics Stack Exchange
Package Summary
| Version | 0.0.0 |
| License | BSD |
| Build type | CATKIN |
| Use | RECOMMENDED |
Repository Summary
| Checkout URI | https://github.com/SMRT-AIST/fast_gicp.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2025-04-24 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Package Description
Additional Links
Maintainers
- k.koide
Authors
Note: New faster library is released
We released small_gicp that is twice as fast as fast_gicp and with minimum dependencies and clean interfaces.
fast_gicp
This package is a collection of GICP-based fast point cloud registration algorithms. It constains a multi-threaded GICP as well as multi-thread and GPU implementations of our voxelized GICP (VGICP) algorithm. All the implemented algorithms have the PCL registration interface so that they can be used as an inplace replacement for GICP in PCL.
- FastGICP: multi-threaded GICP algorithm (~40FPS)
- FastGICPSingleThread: GICP algorithm optimized for single-threading (~15FPS)
- FastVGICP: multi-threaded and voxelized GICP algorithm (~70FPS)
- FastVGICPCuda: CUDA-accelerated voxelized GICP algorithm (~120FPS)
- NDTCuda: CUDA-accelerated D2D NDT algorithm (~500FPS)
![]() on melodic & noetic
on melodic & noetic
Installation
Dependencies
We have tested this package on Ubuntu 18.04/20.04 and CUDA 11.1.
On macOS when using brew, you might have to set up your depenencies like this
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
CUDA
To enable the CUDA-powered implementations, set
``` cmake option to
```ON
```.
### ROS
```bash
cd ~/catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
Non-ROS
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8
Python bindings
cd fast_gicp
python3 setup.py install --user
Note: If you are on a catkin-enabled environment and the installation doesn’t work well, comment out
find_package(catkin)
in CMakeLists.txt and run the above installation command again.
```python import pygicp
target = # Nx3 numpy array source = # Mx3 numpy array
1. function interface
matrix = pygicp.align_points(target, source)
optional arguments
initial_guess : Initial guess of the relative pose (4x4 matrix)
method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
downsample_resolution : Downsampling resolution (used only if positive)
k_correspondences : Number of points used for covariance estimation
max_correspondence_distance : Maximum distance for corresponding point search
voxel_resolution : Resolution of voxel-based algorithms
neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
num_threads : Number of threads
2. class interface
you may want to downsample the input clouds before registration
target = pygicp.downsample(target, 0.25) source = pygicp.downsample(source, 0.25)
pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp.FastGICP() gicp.set_input_target(target) gicp.set_input_source(source) matrix = gicp.align()
optional
File truncated at 100 lines see the full file
Package Dependencies
| Deps | Name |
|---|---|
| ros_environment | |
| catkin | |
| ament_cmake |
System Dependencies
| Name |
|---|
| libpcl-all-dev |
| eigen |
Dependant Packages
| Name | Deps |
|---|---|
| lidar_situational_graphs |
Launch files
Messages
Services
Plugins
Recent questions tagged fast_gicp at Robotics Stack Exchange
Package Summary
| Version | 0.0.0 |
| License | BSD |
| Build type | CATKIN |
| Use | RECOMMENDED |
Repository Summary
| Checkout URI | https://github.com/SMRT-AIST/fast_gicp.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2025-04-24 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Package Description
Additional Links
Maintainers
- k.koide
Authors
Note: New faster library is released
We released small_gicp that is twice as fast as fast_gicp and with minimum dependencies and clean interfaces.
fast_gicp
This package is a collection of GICP-based fast point cloud registration algorithms. It constains a multi-threaded GICP as well as multi-thread and GPU implementations of our voxelized GICP (VGICP) algorithm. All the implemented algorithms have the PCL registration interface so that they can be used as an inplace replacement for GICP in PCL.
- FastGICP: multi-threaded GICP algorithm (~40FPS)
- FastGICPSingleThread: GICP algorithm optimized for single-threading (~15FPS)
- FastVGICP: multi-threaded and voxelized GICP algorithm (~70FPS)
- FastVGICPCuda: CUDA-accelerated voxelized GICP algorithm (~120FPS)
- NDTCuda: CUDA-accelerated D2D NDT algorithm (~500FPS)
![]() on melodic & noetic
on melodic & noetic
Installation
Dependencies
We have tested this package on Ubuntu 18.04/20.04 and CUDA 11.1.
On macOS when using brew, you might have to set up your depenencies like this
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
CUDA
To enable the CUDA-powered implementations, set
``` cmake option to
```ON
```.
### ROS
```bash
cd ~/catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
Non-ROS
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8
Python bindings
cd fast_gicp
python3 setup.py install --user
Note: If you are on a catkin-enabled environment and the installation doesn’t work well, comment out
find_package(catkin)
in CMakeLists.txt and run the above installation command again.
```python import pygicp
target = # Nx3 numpy array source = # Mx3 numpy array
1. function interface
matrix = pygicp.align_points(target, source)
optional arguments
initial_guess : Initial guess of the relative pose (4x4 matrix)
method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
downsample_resolution : Downsampling resolution (used only if positive)
k_correspondences : Number of points used for covariance estimation
max_correspondence_distance : Maximum distance for corresponding point search
voxel_resolution : Resolution of voxel-based algorithms
neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
num_threads : Number of threads
2. class interface
you may want to downsample the input clouds before registration
target = pygicp.downsample(target, 0.25) source = pygicp.downsample(source, 0.25)
pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp.FastGICP() gicp.set_input_target(target) gicp.set_input_source(source) matrix = gicp.align()
optional
File truncated at 100 lines see the full file
Package Dependencies
| Deps | Name |
|---|---|
| ros_environment | |
| catkin | |
| ament_cmake |
System Dependencies
| Name |
|---|
| libpcl-all-dev |
| eigen |
Dependant Packages
| Name | Deps |
|---|---|
| lidar_situational_graphs |
Launch files
Messages
Services
Plugins
Recent questions tagged fast_gicp at Robotics Stack Exchange
Package Summary
| Version | 0.0.0 |
| License | BSD |
| Build type | CATKIN |
| Use | RECOMMENDED |
Repository Summary
| Checkout URI | https://github.com/SMRT-AIST/fast_gicp.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2025-04-24 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Package Description
Additional Links
Maintainers
- k.koide
Authors
Note: New faster library is released
We released small_gicp that is twice as fast as fast_gicp and with minimum dependencies and clean interfaces.
fast_gicp
This package is a collection of GICP-based fast point cloud registration algorithms. It constains a multi-threaded GICP as well as multi-thread and GPU implementations of our voxelized GICP (VGICP) algorithm. All the implemented algorithms have the PCL registration interface so that they can be used as an inplace replacement for GICP in PCL.
- FastGICP: multi-threaded GICP algorithm (~40FPS)
- FastGICPSingleThread: GICP algorithm optimized for single-threading (~15FPS)
- FastVGICP: multi-threaded and voxelized GICP algorithm (~70FPS)
- FastVGICPCuda: CUDA-accelerated voxelized GICP algorithm (~120FPS)
- NDTCuda: CUDA-accelerated D2D NDT algorithm (~500FPS)
![]() on melodic & noetic
on melodic & noetic
Installation
Dependencies
We have tested this package on Ubuntu 18.04/20.04 and CUDA 11.1.
On macOS when using brew, you might have to set up your depenencies like this
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
CUDA
To enable the CUDA-powered implementations, set
``` cmake option to
```ON
```.
### ROS
```bash
cd ~/catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
Non-ROS
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8
Python bindings
cd fast_gicp
python3 setup.py install --user
Note: If you are on a catkin-enabled environment and the installation doesn’t work well, comment out
find_package(catkin)
in CMakeLists.txt and run the above installation command again.
```python import pygicp
target = # Nx3 numpy array source = # Mx3 numpy array
1. function interface
matrix = pygicp.align_points(target, source)
optional arguments
initial_guess : Initial guess of the relative pose (4x4 matrix)
method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
downsample_resolution : Downsampling resolution (used only if positive)
k_correspondences : Number of points used for covariance estimation
max_correspondence_distance : Maximum distance for corresponding point search
voxel_resolution : Resolution of voxel-based algorithms
neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
num_threads : Number of threads
2. class interface
you may want to downsample the input clouds before registration
target = pygicp.downsample(target, 0.25) source = pygicp.downsample(source, 0.25)
pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp.FastGICP() gicp.set_input_target(target) gicp.set_input_source(source) matrix = gicp.align()
optional
File truncated at 100 lines see the full file
Package Dependencies
| Deps | Name |
|---|---|
| ros_environment | |
| catkin | |
| ament_cmake |
System Dependencies
| Name |
|---|
| libpcl-all-dev |
| eigen |
Dependant Packages
| Name | Deps |
|---|---|
| lidar_situational_graphs |