
Repository Summary
| Checkout URI | https://github.com/ros-perception/vision_msgs.git |
| VCS Type | git |
| VCS Version | ros2 |
| Last Updated | 2026-01-14 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| vision_msgs | 4.2.0 |
| vision_msgs_rviz_plugins | 4.2.0 |
README
ROS Vision Messages
Introduction
This package defines a set of messages to unify computer vision and object detection efforts in ROS.
Overview
The messages in this package are to define a common outward-facing interface for vision-based pipelines. The set of messages here are meant to enable 2 primary types of pipelines:
- “Pure” Classifiers, which identify class probabilities given a single sensor input
- Detectors, which identify class probabilities as well as the poses of those classes given a sensor input
The class probabilities are stored with an array of ObjectHypothesis messages, which is essentially a map from integer IDs to float scores and poses.
Message types exist separately for 2D and 3D. The metadata that is stored for each object is application-specific, and so this package places very few constraints on the metadata. Each possible detection result must have a unique numerical ID so that it can be unambiguously and efficiently identified in the results messages. Object metadata such as name, mesh, etc. can then be looked up from a database.
The only other requirement is that the metadata database information can be stored in a ROS parameter. We expect a classifier to load the database (or detailed database connection information) to the parameter server in a manner similar to how URDFs are loaded and stored there (see [6]), most likely defined in an XML format. This expectation may be further refined in the future using a ROS Enhancement Proposal, or REP [7].
We also would like classifiers to have a way to signal when the database has been updated, so that listeners can respond accordingly. The database might be updated in the case of online learning. To solve this problem, each classifier can publish messages to a topic signaling that the database has been updated, as well as incrementing a database version that’s continually published with the classifier information.
Source data that generated a classification or detection are not a part of the messages. If you need to access them, use an exact or approximate time synchronizer in your code, as the message’s header should match the header of the source data.
Semantic segmentation pipelines should use sensor_msgs/Image messages for publishing segmentation and confidence masks. This allows systems to use standard ROS tools for image processing, and allows choosing the most compact image encoding appropriate for the task. To transmit the metadata associated with the vision pipeline, you should use the /vision_msgs/LabelInfo message. This message works the same as /sensor_msgs/CameraInfo or /vision_msgs/VisionInfo:
-
Publish
LabelInfoto a topic. The topic should be at same namespace level as the associated image. That is, if your image is published at/my_segmentation_node/image, theLabelInfoshould be published at/my_segmentation_node/label_info. Use a latched publisher forLabelInfo, so that new nodes joining the ROS system can get the messages that were published since the beginning. In ROS2, this can be achieved using atransient localQoS profile. -
The subscribing node can get and store one
LabelInfomessage and cancel its subscription after that. This assumes the provider of the message publishes it periodically.
Messages
- Classification: pure classification without pose
- Detection2D and Detection3D: classification + pose
- BoundingBox2D, BoundingBox3D: orientable rectangular bounding boxes, specified by the pose of their center and their size.
- XArray messages, where X is one of the message types listed above. A pipeline should emit XArray messages as its forward-facing ROS interface.
- VisionInfo: Information about a classifier, such as its name and where to find its metadata database.
- ObjectHypothesis: An class_id/score pair.
- ObjectHypothesisWithPose: An ObjectHypothesis/pose pair. This accounts for the fact that a single input, say, a point cloud, could have different poses depdending on its class. For example, a flat rectangular prism could either be a smartphone lying on its back, or a book lying on its side.
By using a very general message definition, we hope to cover as many of the various computer vision use cases as possible. Some examples of use cases that can be fully represented are:
- Bounding box multi-object detectors with tight bounding box predictions, such as YOLO [1]
- Class-predicting full-image detectors, such as TensorFlow examples trained on the MNIST dataset [2]
- Full 6D-pose recognition pipelines, such as LINEMOD [3] and those included in the Object Recognition Kitchen [4]
- Custom detectors that use various point-cloud based features to predict object attributes (one example is [5])
Please see the vision_msgs_examples repository for some sample vision
pipelines that emit results using the vision_msgs format.
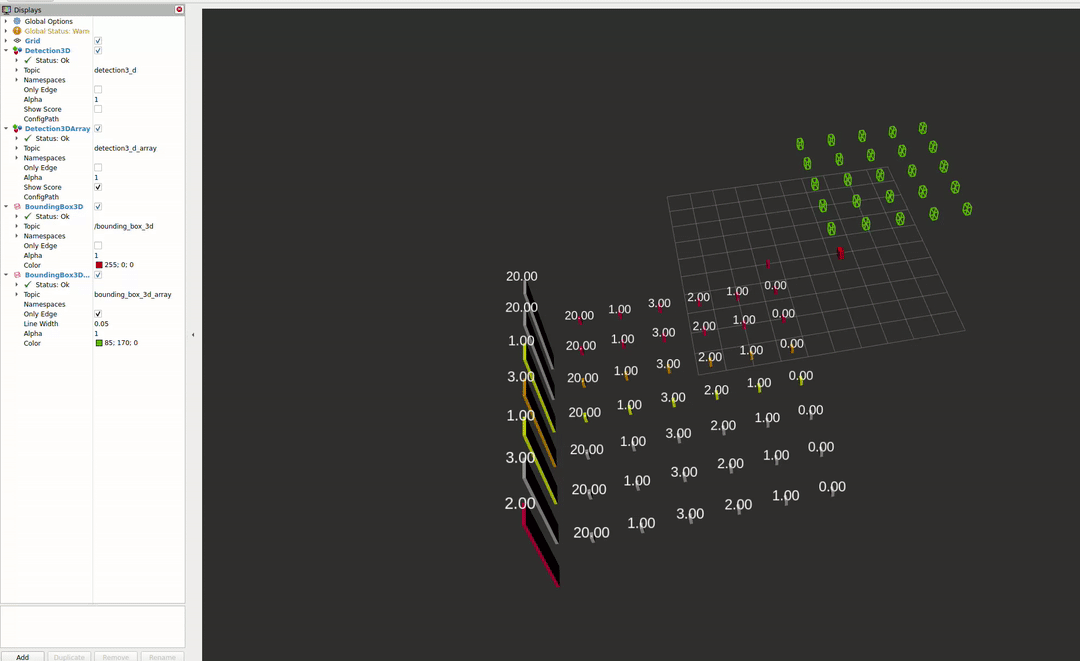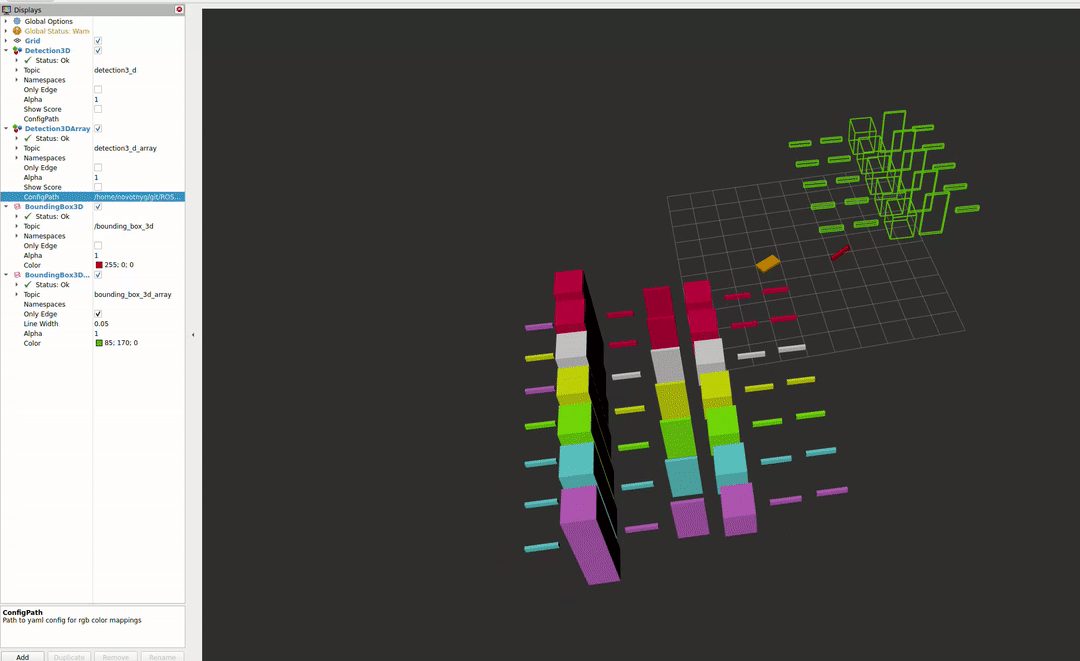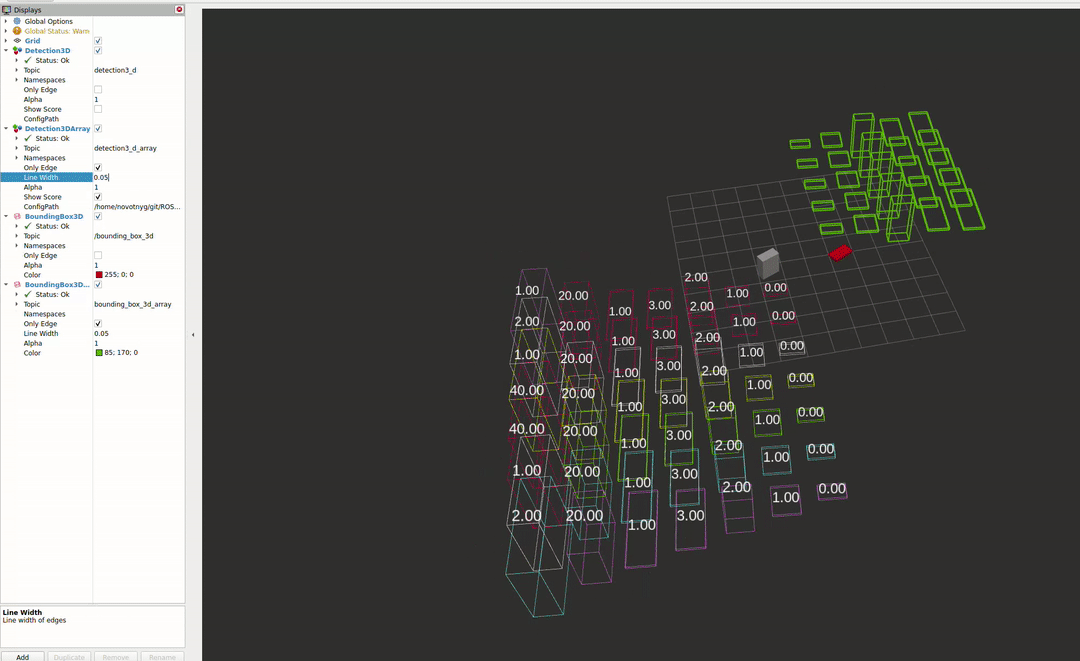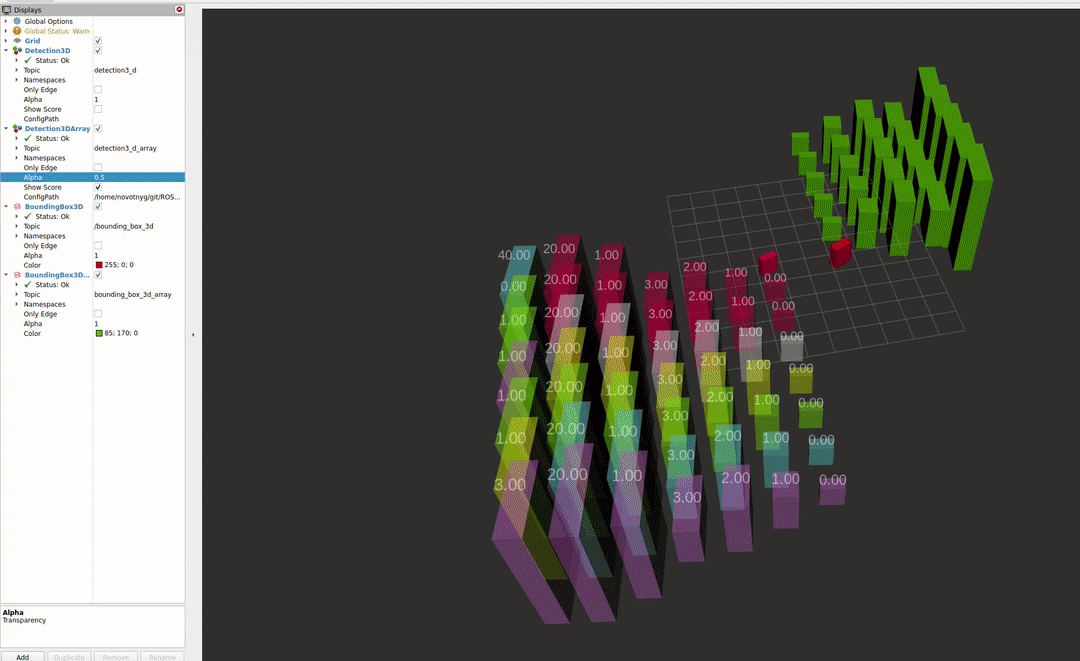
RVIZ Plugins
The second package enables the visualisation of different detectors in RVIZ2. For more information about the capabilities, please see the README file.
References
- [1] YOLO
- [2] TensorFlow MNIST
- [3] LINEMOD
- [4] Object Recognition Kitchen
- [5] Attribute Detector
File truncated at 100 lines see the full file
CONTRIBUTING
Contributions to this repository are welcome. Please open a pull request to submit a contribution.
If you have questions about what types of messages would be considered in scope for this project, please create a GitHub issue to discuss your idea.
Any contribution that you make to this repository will be under the Apache 2 License, as dictated by that license:
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
Repository Summary
| Checkout URI | https://github.com/ros-perception/vision_msgs.git |
| VCS Type | git |
| VCS Version | ros2 |
| Last Updated | 2026-01-14 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| vision_msgs | 4.2.0 |
| vision_msgs_rviz_plugins | 4.2.0 |
README
ROS Vision Messages
Introduction
This package defines a set of messages to unify computer vision and object detection efforts in ROS.
Overview
The messages in this package are to define a common outward-facing interface for vision-based pipelines. The set of messages here are meant to enable 2 primary types of pipelines:
- “Pure” Classifiers, which identify class probabilities given a single sensor input
- Detectors, which identify class probabilities as well as the poses of those classes given a sensor input
The class probabilities are stored with an array of ObjectHypothesis messages, which is essentially a map from integer IDs to float scores and poses.
Message types exist separately for 2D and 3D. The metadata that is stored for each object is application-specific, and so this package places very few constraints on the metadata. Each possible detection result must have a unique numerical ID so that it can be unambiguously and efficiently identified in the results messages. Object metadata such as name, mesh, etc. can then be looked up from a database.
The only other requirement is that the metadata database information can be stored in a ROS parameter. We expect a classifier to load the database (or detailed database connection information) to the parameter server in a manner similar to how URDFs are loaded and stored there (see [6]), most likely defined in an XML format. This expectation may be further refined in the future using a ROS Enhancement Proposal, or REP [7].
We also would like classifiers to have a way to signal when the database has been updated, so that listeners can respond accordingly. The database might be updated in the case of online learning. To solve this problem, each classifier can publish messages to a topic signaling that the database has been updated, as well as incrementing a database version that’s continually published with the classifier information.
Source data that generated a classification or detection are not a part of the messages. If you need to access them, use an exact or approximate time synchronizer in your code, as the message’s header should match the header of the source data.
Semantic segmentation pipelines should use sensor_msgs/Image messages for publishing segmentation and confidence masks. This allows systems to use standard ROS tools for image processing, and allows choosing the most compact image encoding appropriate for the task. To transmit the metadata associated with the vision pipeline, you should use the /vision_msgs/LabelInfo message. This message works the same as /sensor_msgs/CameraInfo or /vision_msgs/VisionInfo:
-
Publish
LabelInfoto a topic. The topic should be at same namespace level as the associated image. That is, if your image is published at/my_segmentation_node/image, theLabelInfoshould be published at/my_segmentation_node/label_info. Use a latched publisher forLabelInfo, so that new nodes joining the ROS system can get the messages that were published since the beginning. In ROS2, this can be achieved using atransient localQoS profile. -
The subscribing node can get and store one
LabelInfomessage and cancel its subscription after that. This assumes the provider of the message publishes it periodically.
Messages
- Classification: pure classification without pose
- Detection2D and Detection3D: classification + pose
- BoundingBox2D, BoundingBox3D: orientable rectangular bounding boxes, specified by the pose of their center and their size.
- XArray messages, where X is one of the message types listed above. A pipeline should emit XArray messages as its forward-facing ROS interface.
- VisionInfo: Information about a classifier, such as its name and where to find its metadata database.
- ObjectHypothesis: An class_id/score pair.
- ObjectHypothesisWithPose: An ObjectHypothesis/pose pair. This accounts for the fact that a single input, say, a point cloud, could have different poses depdending on its class. For example, a flat rectangular prism could either be a smartphone lying on its back, or a book lying on its side.
By using a very general message definition, we hope to cover as many of the various computer vision use cases as possible. Some examples of use cases that can be fully represented are:
- Bounding box multi-object detectors with tight bounding box predictions, such as YOLO [1]
- Class-predicting full-image detectors, such as TensorFlow examples trained on the MNIST dataset [2]
- Full 6D-pose recognition pipelines, such as LINEMOD [3] and those included in the Object Recognition Kitchen [4]
- Custom detectors that use various point-cloud based features to predict object attributes (one example is [5])
Please see the vision_msgs_examples repository for some sample vision
pipelines that emit results using the vision_msgs format.
RVIZ Plugins
The second package enables the visualisation of different detectors in RVIZ2. For more information about the capabilities, please see the README file.
References
- [1] YOLO
- [2] TensorFlow MNIST
- [3] LINEMOD
- [4] Object Recognition Kitchen
- [5] Attribute Detector
File truncated at 100 lines see the full file
CONTRIBUTING
Contributions to this repository are welcome. Please open a pull request to submit a contribution.
If you have questions about what types of messages would be considered in scope for this project, please create a GitHub issue to discuss your idea.
Any contribution that you make to this repository will be under the Apache 2 License, as dictated by that license:
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
Repository Summary
| Checkout URI | https://github.com/ros-perception/vision_msgs.git |
| VCS Type | git |
| VCS Version | ros2 |
| Last Updated | 2026-01-14 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| vision_msgs | 4.2.0 |
| vision_msgs_rviz_plugins | 4.2.0 |
README
ROS Vision Messages
Introduction
This package defines a set of messages to unify computer vision and object detection efforts in ROS.
Overview
The messages in this package are to define a common outward-facing interface for vision-based pipelines. The set of messages here are meant to enable 2 primary types of pipelines:
- “Pure” Classifiers, which identify class probabilities given a single sensor input
- Detectors, which identify class probabilities as well as the poses of those classes given a sensor input
The class probabilities are stored with an array of ObjectHypothesis messages, which is essentially a map from integer IDs to float scores and poses.
Message types exist separately for 2D and 3D. The metadata that is stored for each object is application-specific, and so this package places very few constraints on the metadata. Each possible detection result must have a unique numerical ID so that it can be unambiguously and efficiently identified in the results messages. Object metadata such as name, mesh, etc. can then be looked up from a database.
The only other requirement is that the metadata database information can be stored in a ROS parameter. We expect a classifier to load the database (or detailed database connection information) to the parameter server in a manner similar to how URDFs are loaded and stored there (see [6]), most likely defined in an XML format. This expectation may be further refined in the future using a ROS Enhancement Proposal, or REP [7].
We also would like classifiers to have a way to signal when the database has been updated, so that listeners can respond accordingly. The database might be updated in the case of online learning. To solve this problem, each classifier can publish messages to a topic signaling that the database has been updated, as well as incrementing a database version that’s continually published with the classifier information.
Source data that generated a classification or detection are not a part of the messages. If you need to access them, use an exact or approximate time synchronizer in your code, as the message’s header should match the header of the source data.
Semantic segmentation pipelines should use sensor_msgs/Image messages for publishing segmentation and confidence masks. This allows systems to use standard ROS tools for image processing, and allows choosing the most compact image encoding appropriate for the task. To transmit the metadata associated with the vision pipeline, you should use the /vision_msgs/LabelInfo message. This message works the same as /sensor_msgs/CameraInfo or /vision_msgs/VisionInfo:
-
Publish
LabelInfoto a topic. The topic should be at same namespace level as the associated image. That is, if your image is published at/my_segmentation_node/image, theLabelInfoshould be published at/my_segmentation_node/label_info. Use a latched publisher forLabelInfo, so that new nodes joining the ROS system can get the messages that were published since the beginning. In ROS2, this can be achieved using atransient localQoS profile. -
The subscribing node can get and store one
LabelInfomessage and cancel its subscription after that. This assumes the provider of the message publishes it periodically.
Messages
- Classification: pure classification without pose
- Detection2D and Detection3D: classification + pose
- BoundingBox2D, BoundingBox3D: orientable rectangular bounding boxes, specified by the pose of their center and their size.
- XArray messages, where X is one of the message types listed above. A pipeline should emit XArray messages as its forward-facing ROS interface.
- VisionInfo: Information about a classifier, such as its name and where to find its metadata database.
- ObjectHypothesis: An class_id/score pair.
- ObjectHypothesisWithPose: An ObjectHypothesis/pose pair. This accounts for the fact that a single input, say, a point cloud, could have different poses depdending on its class. For example, a flat rectangular prism could either be a smartphone lying on its back, or a book lying on its side.
By using a very general message definition, we hope to cover as many of the various computer vision use cases as possible. Some examples of use cases that can be fully represented are:
- Bounding box multi-object detectors with tight bounding box predictions, such as YOLO [1]
- Class-predicting full-image detectors, such as TensorFlow examples trained on the MNIST dataset [2]
- Full 6D-pose recognition pipelines, such as LINEMOD [3] and those included in the Object Recognition Kitchen [4]
- Custom detectors that use various point-cloud based features to predict object attributes (one example is [5])
Please see the vision_msgs_examples repository for some sample vision
pipelines that emit results using the vision_msgs format.
RVIZ Plugins
The second package enables the visualisation of different detectors in RVIZ2. For more information about the capabilities, please see the README file.
References
- [1] YOLO
- [2] TensorFlow MNIST
- [3] LINEMOD
- [4] Object Recognition Kitchen
- [5] Attribute Detector
File truncated at 100 lines see the full file
CONTRIBUTING
Contributions to this repository are welcome. Please open a pull request to submit a contribution.
If you have questions about what types of messages would be considered in scope for this project, please create a GitHub issue to discuss your idea.
Any contribution that you make to this repository will be under the Apache 2 License, as dictated by that license:
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
Repository Summary
| Checkout URI | https://github.com/ros-perception/vision_msgs.git |
| VCS Type | git |
| VCS Version | ros2 |
| Last Updated | 2026-01-14 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| vision_msgs | 4.2.0 |
| vision_msgs_rviz_plugins | 4.2.0 |
README
ROS Vision Messages
Introduction
This package defines a set of messages to unify computer vision and object detection efforts in ROS.
Overview
The messages in this package are to define a common outward-facing interface for vision-based pipelines. The set of messages here are meant to enable 2 primary types of pipelines:
- “Pure” Classifiers, which identify class probabilities given a single sensor input
- Detectors, which identify class probabilities as well as the poses of those classes given a sensor input
The class probabilities are stored with an array of ObjectHypothesis messages, which is essentially a map from integer IDs to float scores and poses.
Message types exist separately for 2D and 3D. The metadata that is stored for each object is application-specific, and so this package places very few constraints on the metadata. Each possible detection result must have a unique numerical ID so that it can be unambiguously and efficiently identified in the results messages. Object metadata such as name, mesh, etc. can then be looked up from a database.
The only other requirement is that the metadata database information can be stored in a ROS parameter. We expect a classifier to load the database (or detailed database connection information) to the parameter server in a manner similar to how URDFs are loaded and stored there (see [6]), most likely defined in an XML format. This expectation may be further refined in the future using a ROS Enhancement Proposal, or REP [7].
We also would like classifiers to have a way to signal when the database has been updated, so that listeners can respond accordingly. The database might be updated in the case of online learning. To solve this problem, each classifier can publish messages to a topic signaling that the database has been updated, as well as incrementing a database version that’s continually published with the classifier information.
Source data that generated a classification or detection are not a part of the messages. If you need to access them, use an exact or approximate time synchronizer in your code, as the message’s header should match the header of the source data.
Semantic segmentation pipelines should use sensor_msgs/Image messages for publishing segmentation and confidence masks. This allows systems to use standard ROS tools for image processing, and allows choosing the most compact image encoding appropriate for the task. To transmit the metadata associated with the vision pipeline, you should use the /vision_msgs/LabelInfo message. This message works the same as /sensor_msgs/CameraInfo or /vision_msgs/VisionInfo:
-
Publish
LabelInfoto a topic. The topic should be at same namespace level as the associated image. That is, if your image is published at/my_segmentation_node/image, theLabelInfoshould be published at/my_segmentation_node/label_info. Use a latched publisher forLabelInfo, so that new nodes joining the ROS system can get the messages that were published since the beginning. In ROS2, this can be achieved using atransient localQoS profile. -
The subscribing node can get and store one
LabelInfomessage and cancel its subscription after that. This assumes the provider of the message publishes it periodically.
Messages
- Classification: pure classification without pose
- Detection2D and Detection3D: classification + pose
- BoundingBox2D, BoundingBox3D: orientable rectangular bounding boxes, specified by the pose of their center and their size.
- XArray messages, where X is one of the message types listed above. A pipeline should emit XArray messages as its forward-facing ROS interface.
- VisionInfo: Information about a classifier, such as its name and where to find its metadata database.
- ObjectHypothesis: An class_id/score pair.
- ObjectHypothesisWithPose: An ObjectHypothesis/pose pair. This accounts for the fact that a single input, say, a point cloud, could have different poses depdending on its class. For example, a flat rectangular prism could either be a smartphone lying on its back, or a book lying on its side.
By using a very general message definition, we hope to cover as many of the various computer vision use cases as possible. Some examples of use cases that can be fully represented are:
- Bounding box multi-object detectors with tight bounding box predictions, such as YOLO [1]
- Class-predicting full-image detectors, such as TensorFlow examples trained on the MNIST dataset [2]
- Full 6D-pose recognition pipelines, such as LINEMOD [3] and those included in the Object Recognition Kitchen [4]
- Custom detectors that use various point-cloud based features to predict object attributes (one example is [5])
Please see the vision_msgs_examples repository for some sample vision
pipelines that emit results using the vision_msgs format.
RVIZ Plugins
The second package enables the visualisation of different detectors in RVIZ2. For more information about the capabilities, please see the README file.
References
- [1] YOLO
- [2] TensorFlow MNIST
- [3] LINEMOD
- [4] Object Recognition Kitchen
- [5] Attribute Detector
File truncated at 100 lines see the full file
CONTRIBUTING
Contributions to this repository are welcome. Please open a pull request to submit a contribution.
If you have questions about what types of messages would be considered in scope for this project, please create a GitHub issue to discuss your idea.
Any contribution that you make to this repository will be under the Apache 2 License, as dictated by that license:
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
Repository Summary
| Checkout URI | https://github.com/ros-perception/vision_msgs.git |
| VCS Type | git |
| VCS Version | ros2 |
| Last Updated | 2026-01-14 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| vision_msgs | 4.2.0 |
| vision_msgs_rviz_plugins | 4.2.0 |
README
ROS Vision Messages
Introduction
This package defines a set of messages to unify computer vision and object detection efforts in ROS.
Overview
The messages in this package are to define a common outward-facing interface for vision-based pipelines. The set of messages here are meant to enable 2 primary types of pipelines:
- “Pure” Classifiers, which identify class probabilities given a single sensor input
- Detectors, which identify class probabilities as well as the poses of those classes given a sensor input
The class probabilities are stored with an array of ObjectHypothesis messages, which is essentially a map from integer IDs to float scores and poses.
Message types exist separately for 2D and 3D. The metadata that is stored for each object is application-specific, and so this package places very few constraints on the metadata. Each possible detection result must have a unique numerical ID so that it can be unambiguously and efficiently identified in the results messages. Object metadata such as name, mesh, etc. can then be looked up from a database.
The only other requirement is that the metadata database information can be stored in a ROS parameter. We expect a classifier to load the database (or detailed database connection information) to the parameter server in a manner similar to how URDFs are loaded and stored there (see [6]), most likely defined in an XML format. This expectation may be further refined in the future using a ROS Enhancement Proposal, or REP [7].
We also would like classifiers to have a way to signal when the database has been updated, so that listeners can respond accordingly. The database might be updated in the case of online learning. To solve this problem, each classifier can publish messages to a topic signaling that the database has been updated, as well as incrementing a database version that’s continually published with the classifier information.
Source data that generated a classification or detection are not a part of the messages. If you need to access them, use an exact or approximate time synchronizer in your code, as the message’s header should match the header of the source data.
Semantic segmentation pipelines should use sensor_msgs/Image messages for publishing segmentation and confidence masks. This allows systems to use standard ROS tools for image processing, and allows choosing the most compact image encoding appropriate for the task. To transmit the metadata associated with the vision pipeline, you should use the /vision_msgs/LabelInfo message. This message works the same as /sensor_msgs/CameraInfo or /vision_msgs/VisionInfo:
-
Publish
LabelInfoto a topic. The topic should be at same namespace level as the associated image. That is, if your image is published at/my_segmentation_node/image, theLabelInfoshould be published at/my_segmentation_node/label_info. Use a latched publisher forLabelInfo, so that new nodes joining the ROS system can get the messages that were published since the beginning. In ROS2, this can be achieved using atransient localQoS profile. -
The subscribing node can get and store one
LabelInfomessage and cancel its subscription after that. This assumes the provider of the message publishes it periodically.
Messages
- Classification: pure classification without pose
- Detection2D and Detection3D: classification + pose
- BoundingBox2D, BoundingBox3D: orientable rectangular bounding boxes, specified by the pose of their center and their size.
- XArray messages, where X is one of the message types listed above. A pipeline should emit XArray messages as its forward-facing ROS interface.
- VisionInfo: Information about a classifier, such as its name and where to find its metadata database.
- ObjectHypothesis: An class_id/score pair.
- ObjectHypothesisWithPose: An ObjectHypothesis/pose pair. This accounts for the fact that a single input, say, a point cloud, could have different poses depdending on its class. For example, a flat rectangular prism could either be a smartphone lying on its back, or a book lying on its side.
By using a very general message definition, we hope to cover as many of the various computer vision use cases as possible. Some examples of use cases that can be fully represented are:
- Bounding box multi-object detectors with tight bounding box predictions, such as YOLO [1]
- Class-predicting full-image detectors, such as TensorFlow examples trained on the MNIST dataset [2]
- Full 6D-pose recognition pipelines, such as LINEMOD [3] and those included in the Object Recognition Kitchen [4]
- Custom detectors that use various point-cloud based features to predict object attributes (one example is [5])
Please see the vision_msgs_examples repository for some sample vision
pipelines that emit results using the vision_msgs format.
RVIZ Plugins
The second package enables the visualisation of different detectors in RVIZ2. For more information about the capabilities, please see the README file.
References
- [1] YOLO
- [2] TensorFlow MNIST
- [3] LINEMOD
- [4] Object Recognition Kitchen
- [5] Attribute Detector
File truncated at 100 lines see the full file
CONTRIBUTING
Contributions to this repository are welcome. Please open a pull request to submit a contribution.
If you have questions about what types of messages would be considered in scope for this project, please create a GitHub issue to discuss your idea.
Any contribution that you make to this repository will be under the Apache 2 License, as dictated by that license:
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
Repository Summary
| Checkout URI | https://github.com/Kukanani/vision_msgs.git |
| VCS Type | git |
| VCS Version | ros2 |
| Last Updated | 2026-01-14 |
| Dev Status | MAINTAINED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| vision_msgs | 4.2.0 |
| vision_msgs_rviz_plugins | 4.2.0 |
README
ROS Vision Messages
Introduction
This package defines a set of messages to unify computer vision and object detection efforts in ROS.
Overview
The messages in this package are to define a common outward-facing interface for vision-based pipelines. The set of messages here are meant to enable 2 primary types of pipelines:
- “Pure” Classifiers, which identify class probabilities given a single sensor input
- Detectors, which identify class probabilities as well as the poses of those classes given a sensor input
The class probabilities are stored with an array of ObjectHypothesis messages, which is essentially a map from integer IDs to float scores and poses.
Message types exist separately for 2D and 3D. The metadata that is stored for each object is application-specific, and so this package places very few constraints on the metadata. Each possible detection result must have a unique numerical ID so that it can be unambiguously and efficiently identified in the results messages. Object metadata such as name, mesh, etc. can then be looked up from a database.
The only other requirement is that the metadata database information can be stored in a ROS parameter. We expect a classifier to load the database (or detailed database connection information) to the parameter server in a manner similar to how URDFs are loaded and stored there (see [6]), most likely defined in an XML format. This expectation may be further refined in the future using a ROS Enhancement Proposal, or REP [7].
We also would like classifiers to have a way to signal when the database has been updated, so that listeners can respond accordingly. The database might be updated in the case of online learning. To solve this problem, each classifier can publish messages to a topic signaling that the database has been updated, as well as incrementing a database version that’s continually published with the classifier information.
Source data that generated a classification or detection are not a part of the messages. If you need to access them, use an exact or approximate time synchronizer in your code, as the message’s header should match the header of the source data.
Semantic segmentation pipelines should use sensor_msgs/Image messages for publishing segmentation and confidence masks. This allows systems to use standard ROS tools for image processing, and allows choosing the most compact image encoding appropriate for the task. To transmit the metadata associated with the vision pipeline, you should use the /vision_msgs/LabelInfo message. This message works the same as /sensor_msgs/CameraInfo or /vision_msgs/VisionInfo:
-
Publish
LabelInfoto a topic. The topic should be at same namespace level as the associated image. That is, if your image is published at/my_segmentation_node/image, theLabelInfoshould be published at/my_segmentation_node/label_info. Use a latched publisher forLabelInfo, so that new nodes joining the ROS system can get the messages that were published since the beginning. In ROS2, this can be achieved using atransient localQoS profile. -
The subscribing node can get and store one
LabelInfomessage and cancel its subscription after that. This assumes the provider of the message publishes it periodically.
Messages
- Classification: pure classification without pose
- Detection2D and Detection3D: classification + pose
- BoundingBox2D, BoundingBox3D: orientable rectangular bounding boxes, specified by the pose of their center and their size.
- XArray messages, where X is one of the message types listed above. A pipeline should emit XArray messages as its forward-facing ROS interface.
- VisionInfo: Information about a classifier, such as its name and where to find its metadata database.
- ObjectHypothesis: An class_id/score pair.
- ObjectHypothesisWithPose: An ObjectHypothesis/pose pair. This accounts for the fact that a single input, say, a point cloud, could have different poses depdending on its class. For example, a flat rectangular prism could either be a smartphone lying on its back, or a book lying on its side.
By using a very general message definition, we hope to cover as many of the various computer vision use cases as possible. Some examples of use cases that can be fully represented are:
- Bounding box multi-object detectors with tight bounding box predictions, such as YOLO [1]
- Class-predicting full-image detectors, such as TensorFlow examples trained on the MNIST dataset [2]
- Full 6D-pose recognition pipelines, such as LINEMOD [3] and those included in the Object Recognition Kitchen [4]
- Custom detectors that use various point-cloud based features to predict object attributes (one example is [5])
Please see the vision_msgs_examples repository for some sample vision
pipelines that emit results using the vision_msgs format.
RVIZ Plugins
The second package enables the visualisation of different detectors in RVIZ2. For more information about the capabilities, please see the README file.
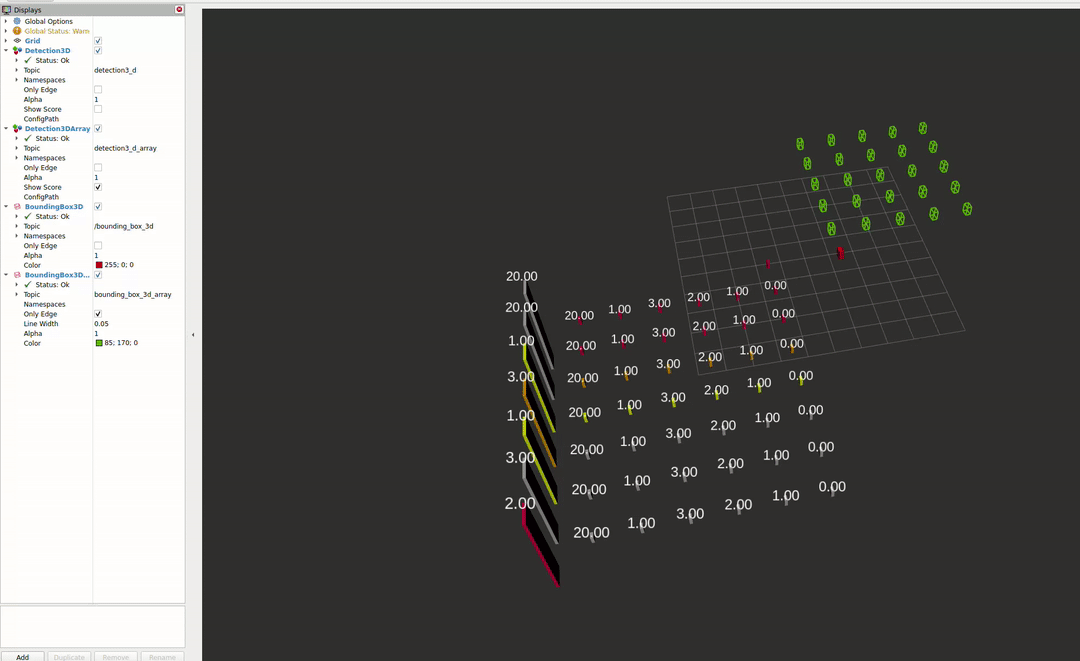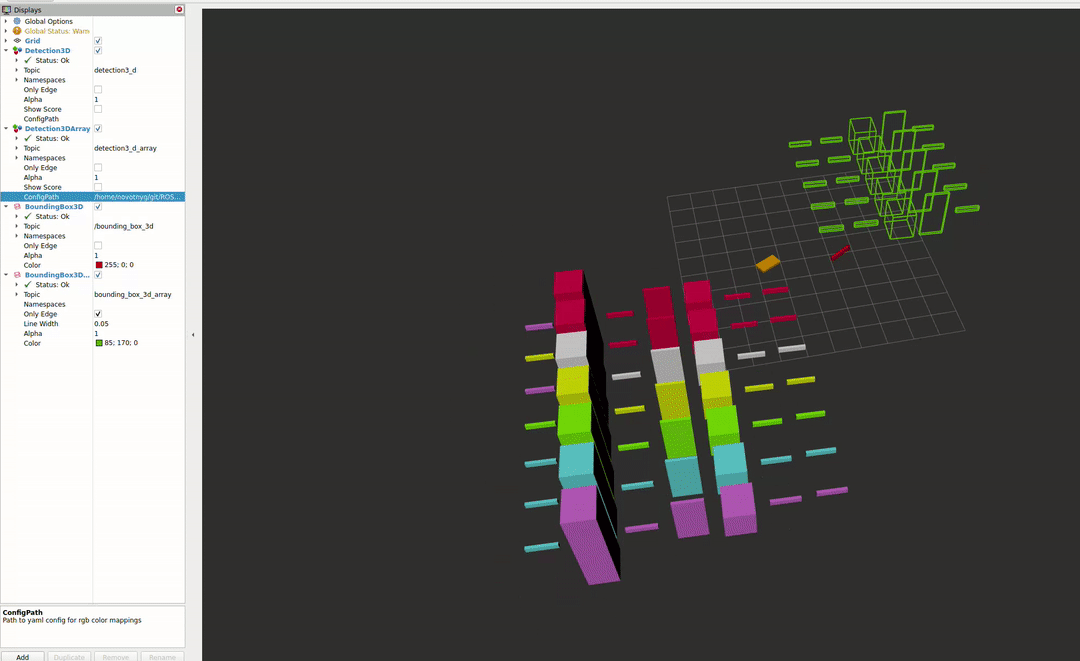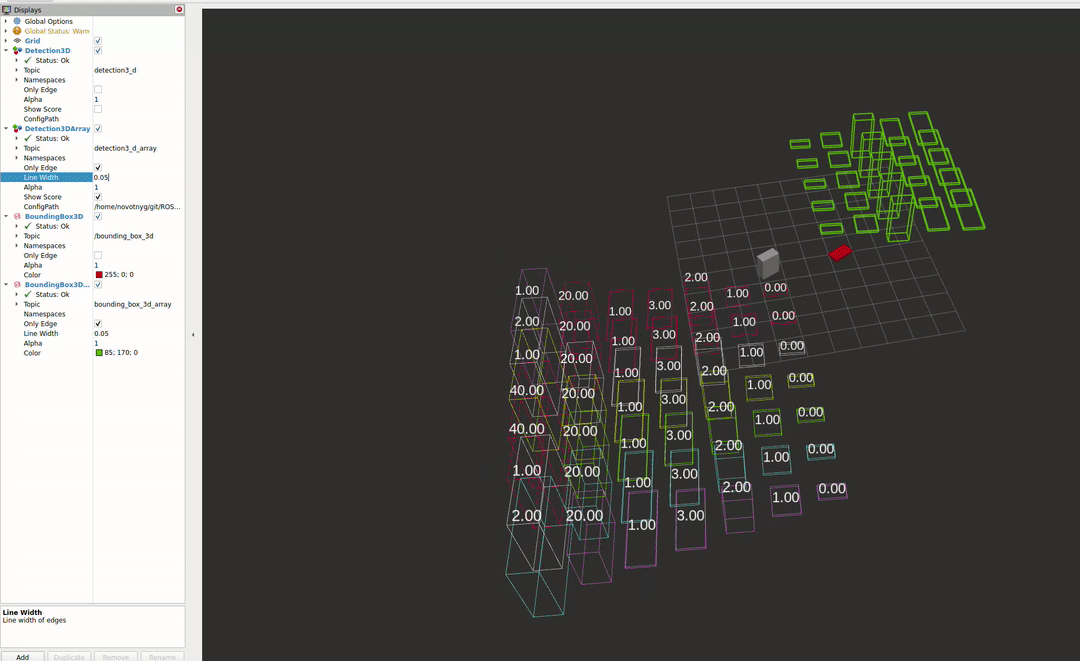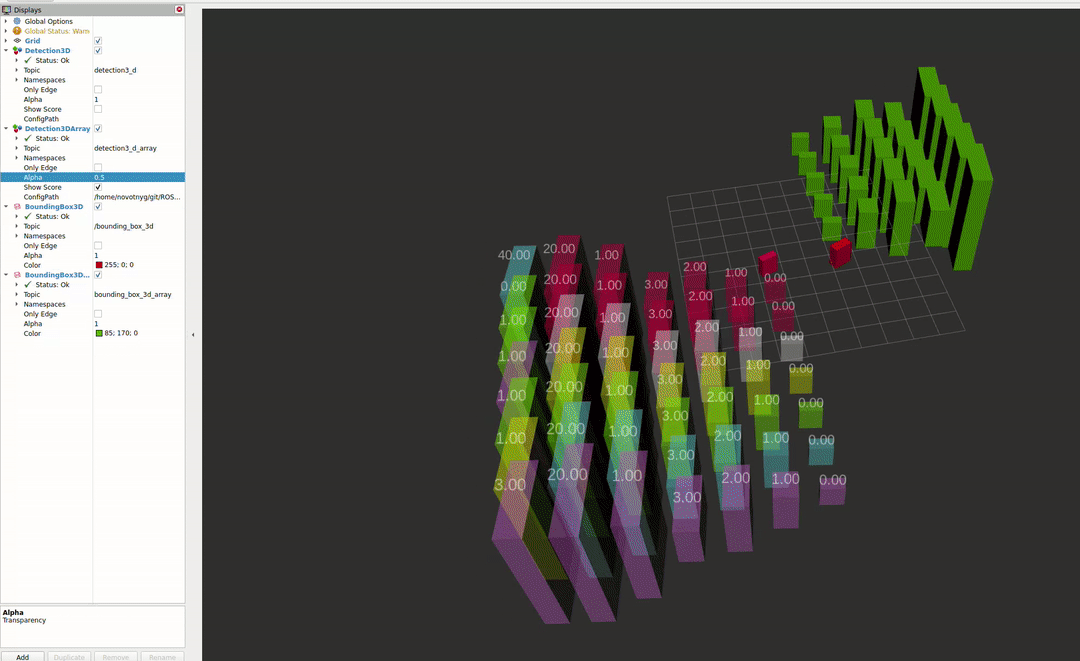
References
- [1] YOLO
- [2] TensorFlow MNIST
- [3] LINEMOD
- [4] Object Recognition Kitchen
- [5] Attribute Detector
File truncated at 100 lines see the full file
CONTRIBUTING
Contributions to this repository are welcome. Please open a pull request to submit a contribution.
If you have questions about what types of messages would be considered in scope for this project, please create a GitHub issue to discuss your idea.
Any contribution that you make to this repository will be under the Apache 2 License, as dictated by that license:
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
Repository Summary
| Checkout URI | https://github.com/ros-perception/vision_msgs.git |
| VCS Type | git |
| VCS Version | ros2 |
| Last Updated | 2026-01-14 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| vision_msgs | 4.2.0 |
| vision_msgs_rviz_plugins | 4.2.0 |
README
ROS Vision Messages
Introduction
This package defines a set of messages to unify computer vision and object detection efforts in ROS.
Overview
The messages in this package are to define a common outward-facing interface for vision-based pipelines. The set of messages here are meant to enable 2 primary types of pipelines:
- “Pure” Classifiers, which identify class probabilities given a single sensor input
- Detectors, which identify class probabilities as well as the poses of those classes given a sensor input
The class probabilities are stored with an array of ObjectHypothesis messages, which is essentially a map from integer IDs to float scores and poses.
Message types exist separately for 2D and 3D. The metadata that is stored for each object is application-specific, and so this package places very few constraints on the metadata. Each possible detection result must have a unique numerical ID so that it can be unambiguously and efficiently identified in the results messages. Object metadata such as name, mesh, etc. can then be looked up from a database.
The only other requirement is that the metadata database information can be stored in a ROS parameter. We expect a classifier to load the database (or detailed database connection information) to the parameter server in a manner similar to how URDFs are loaded and stored there (see [6]), most likely defined in an XML format. This expectation may be further refined in the future using a ROS Enhancement Proposal, or REP [7].
We also would like classifiers to have a way to signal when the database has been updated, so that listeners can respond accordingly. The database might be updated in the case of online learning. To solve this problem, each classifier can publish messages to a topic signaling that the database has been updated, as well as incrementing a database version that’s continually published with the classifier information.
Source data that generated a classification or detection are not a part of the messages. If you need to access them, use an exact or approximate time synchronizer in your code, as the message’s header should match the header of the source data.
Semantic segmentation pipelines should use sensor_msgs/Image messages for publishing segmentation and confidence masks. This allows systems to use standard ROS tools for image processing, and allows choosing the most compact image encoding appropriate for the task. To transmit the metadata associated with the vision pipeline, you should use the /vision_msgs/LabelInfo message. This message works the same as /sensor_msgs/CameraInfo or /vision_msgs/VisionInfo:
-
Publish
LabelInfoto a topic. The topic should be at same namespace level as the associated image. That is, if your image is published at/my_segmentation_node/image, theLabelInfoshould be published at/my_segmentation_node/label_info. Use a latched publisher forLabelInfo, so that new nodes joining the ROS system can get the messages that were published since the beginning. In ROS2, this can be achieved using atransient localQoS profile. -
The subscribing node can get and store one
LabelInfomessage and cancel its subscription after that. This assumes the provider of the message publishes it periodically.
Messages
- Classification: pure classification without pose
- Detection2D and Detection3D: classification + pose
- BoundingBox2D, BoundingBox3D: orientable rectangular bounding boxes, specified by the pose of their center and their size.
- XArray messages, where X is one of the message types listed above. A pipeline should emit XArray messages as its forward-facing ROS interface.
- VisionInfo: Information about a classifier, such as its name and where to find its metadata database.
- ObjectHypothesis: An class_id/score pair.
- ObjectHypothesisWithPose: An ObjectHypothesis/pose pair. This accounts for the fact that a single input, say, a point cloud, could have different poses depdending on its class. For example, a flat rectangular prism could either be a smartphone lying on its back, or a book lying on its side.
By using a very general message definition, we hope to cover as many of the various computer vision use cases as possible. Some examples of use cases that can be fully represented are:
- Bounding box multi-object detectors with tight bounding box predictions, such as YOLO [1]
- Class-predicting full-image detectors, such as TensorFlow examples trained on the MNIST dataset [2]
- Full 6D-pose recognition pipelines, such as LINEMOD [3] and those included in the Object Recognition Kitchen [4]
- Custom detectors that use various point-cloud based features to predict object attributes (one example is [5])
Please see the vision_msgs_examples repository for some sample vision
pipelines that emit results using the vision_msgs format.
RVIZ Plugins
The second package enables the visualisation of different detectors in RVIZ2. For more information about the capabilities, please see the README file.
References
- [1] YOLO
- [2] TensorFlow MNIST
- [3] LINEMOD
- [4] Object Recognition Kitchen
- [5] Attribute Detector
File truncated at 100 lines see the full file
CONTRIBUTING
Contributions to this repository are welcome. Please open a pull request to submit a contribution.
If you have questions about what types of messages would be considered in scope for this project, please create a GitHub issue to discuss your idea.
Any contribution that you make to this repository will be under the Apache 2 License, as dictated by that license:
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
Repository Summary
| Checkout URI | https://github.com/ros-perception/vision_msgs.git |
| VCS Type | git |
| VCS Version | ros2 |
| Last Updated | 2026-01-14 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| vision_msgs | 4.2.0 |
| vision_msgs_rviz_plugins | 4.2.0 |
README
ROS Vision Messages
Introduction
This package defines a set of messages to unify computer vision and object detection efforts in ROS.
Overview
The messages in this package are to define a common outward-facing interface for vision-based pipelines. The set of messages here are meant to enable 2 primary types of pipelines:
- “Pure” Classifiers, which identify class probabilities given a single sensor input
- Detectors, which identify class probabilities as well as the poses of those classes given a sensor input
The class probabilities are stored with an array of ObjectHypothesis messages, which is essentially a map from integer IDs to float scores and poses.
Message types exist separately for 2D and 3D. The metadata that is stored for each object is application-specific, and so this package places very few constraints on the metadata. Each possible detection result must have a unique numerical ID so that it can be unambiguously and efficiently identified in the results messages. Object metadata such as name, mesh, etc. can then be looked up from a database.
The only other requirement is that the metadata database information can be stored in a ROS parameter. We expect a classifier to load the database (or detailed database connection information) to the parameter server in a manner similar to how URDFs are loaded and stored there (see [6]), most likely defined in an XML format. This expectation may be further refined in the future using a ROS Enhancement Proposal, or REP [7].
We also would like classifiers to have a way to signal when the database has been updated, so that listeners can respond accordingly. The database might be updated in the case of online learning. To solve this problem, each classifier can publish messages to a topic signaling that the database has been updated, as well as incrementing a database version that’s continually published with the classifier information.
Source data that generated a classification or detection are not a part of the messages. If you need to access them, use an exact or approximate time synchronizer in your code, as the message’s header should match the header of the source data.
Semantic segmentation pipelines should use sensor_msgs/Image messages for publishing segmentation and confidence masks. This allows systems to use standard ROS tools for image processing, and allows choosing the most compact image encoding appropriate for the task. To transmit the metadata associated with the vision pipeline, you should use the /vision_msgs/LabelInfo message. This message works the same as /sensor_msgs/CameraInfo or /vision_msgs/VisionInfo:
-
Publish
LabelInfoto a topic. The topic should be at same namespace level as the associated image. That is, if your image is published at/my_segmentation_node/image, theLabelInfoshould be published at/my_segmentation_node/label_info. Use a latched publisher forLabelInfo, so that new nodes joining the ROS system can get the messages that were published since the beginning. In ROS2, this can be achieved using atransient localQoS profile. -
The subscribing node can get and store one
LabelInfomessage and cancel its subscription after that. This assumes the provider of the message publishes it periodically.
Messages
- Classification: pure classification without pose
- Detection2D and Detection3D: classification + pose
- BoundingBox2D, BoundingBox3D: orientable rectangular bounding boxes, specified by the pose of their center and their size.
- XArray messages, where X is one of the message types listed above. A pipeline should emit XArray messages as its forward-facing ROS interface.
- VisionInfo: Information about a classifier, such as its name and where to find its metadata database.
- ObjectHypothesis: An class_id/score pair.
- ObjectHypothesisWithPose: An ObjectHypothesis/pose pair. This accounts for the fact that a single input, say, a point cloud, could have different poses depdending on its class. For example, a flat rectangular prism could either be a smartphone lying on its back, or a book lying on its side.
By using a very general message definition, we hope to cover as many of the various computer vision use cases as possible. Some examples of use cases that can be fully represented are:
- Bounding box multi-object detectors with tight bounding box predictions, such as YOLO [1]
- Class-predicting full-image detectors, such as TensorFlow examples trained on the MNIST dataset [2]
- Full 6D-pose recognition pipelines, such as LINEMOD [3] and those included in the Object Recognition Kitchen [4]
- Custom detectors that use various point-cloud based features to predict object attributes (one example is [5])
Please see the vision_msgs_examples repository for some sample vision
pipelines that emit results using the vision_msgs format.
RVIZ Plugins
The second package enables the visualisation of different detectors in RVIZ2. For more information about the capabilities, please see the README file.
References
- [1] YOLO
- [2] TensorFlow MNIST
- [3] LINEMOD
- [4] Object Recognition Kitchen
- [5] Attribute Detector
File truncated at 100 lines see the full file
CONTRIBUTING
Contributions to this repository are welcome. Please open a pull request to submit a contribution.
If you have questions about what types of messages would be considered in scope for this project, please create a GitHub issue to discuss your idea.
Any contribution that you make to this repository will be under the Apache 2 License, as dictated by that license:
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
Repository Summary
| Checkout URI | https://github.com/Kukanani/vision_msgs.git |
| VCS Type | git |
| VCS Version | ros2 |
| Last Updated | 2026-01-14 |
| Dev Status | MAINTAINED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| vision_msgs | 4.2.0 |
| vision_msgs_rviz_plugins | 4.2.0 |
README
ROS Vision Messages
Introduction
This package defines a set of messages to unify computer vision and object detection efforts in ROS.
Overview
The messages in this package are to define a common outward-facing interface for vision-based pipelines. The set of messages here are meant to enable 2 primary types of pipelines:
- “Pure” Classifiers, which identify class probabilities given a single sensor input
- Detectors, which identify class probabilities as well as the poses of those classes given a sensor input
The class probabilities are stored with an array of ObjectHypothesis messages, which is essentially a map from integer IDs to float scores and poses.
Message types exist separately for 2D and 3D. The metadata that is stored for each object is application-specific, and so this package places very few constraints on the metadata. Each possible detection result must have a unique numerical ID so that it can be unambiguously and efficiently identified in the results messages. Object metadata such as name, mesh, etc. can then be looked up from a database.
The only other requirement is that the metadata database information can be stored in a ROS parameter. We expect a classifier to load the database (or detailed database connection information) to the parameter server in a manner similar to how URDFs are loaded and stored there (see [6]), most likely defined in an XML format. This expectation may be further refined in the future using a ROS Enhancement Proposal, or REP [7].
We also would like classifiers to have a way to signal when the database has been updated, so that listeners can respond accordingly. The database might be updated in the case of online learning. To solve this problem, each classifier can publish messages to a topic signaling that the database has been updated, as well as incrementing a database version that’s continually published with the classifier information.
Source data that generated a classification or detection are not a part of the messages. If you need to access them, use an exact or approximate time synchronizer in your code, as the message’s header should match the header of the source data.
Semantic segmentation pipelines should use sensor_msgs/Image messages for publishing segmentation and confidence masks. This allows systems to use standard ROS tools for image processing, and allows choosing the most compact image encoding appropriate for the task. To transmit the metadata associated with the vision pipeline, you should use the /vision_msgs/LabelInfo message. This message works the same as /sensor_msgs/CameraInfo or /vision_msgs/VisionInfo:
-
Publish
LabelInfoto a topic. The topic should be at same namespace level as the associated image. That is, if your image is published at/my_segmentation_node/image, theLabelInfoshould be published at/my_segmentation_node/label_info. Use a latched publisher forLabelInfo, so that new nodes joining the ROS system can get the messages that were published since the beginning. In ROS2, this can be achieved using atransient localQoS profile. -
The subscribing node can get and store one
LabelInfomessage and cancel its subscription after that. This assumes the provider of the message publishes it periodically.
Messages
- Classification: pure classification without pose
- Detection2D and Detection3D: classification + pose
- BoundingBox2D, BoundingBox3D: orientable rectangular bounding boxes, specified by the pose of their center and their size.
- XArray messages, where X is one of the message types listed above. A pipeline should emit XArray messages as its forward-facing ROS interface.
- VisionInfo: Information about a classifier, such as its name and where to find its metadata database.
- ObjectHypothesis: An class_id/score pair.
- ObjectHypothesisWithPose: An ObjectHypothesis/pose pair. This accounts for the fact that a single input, say, a point cloud, could have different poses depdending on its class. For example, a flat rectangular prism could either be a smartphone lying on its back, or a book lying on its side.
By using a very general message definition, we hope to cover as many of the various computer vision use cases as possible. Some examples of use cases that can be fully represented are:
- Bounding box multi-object detectors with tight bounding box predictions, such as YOLO [1]
- Class-predicting full-image detectors, such as TensorFlow examples trained on the MNIST dataset [2]
- Full 6D-pose recognition pipelines, such as LINEMOD [3] and those included in the Object Recognition Kitchen [4]
- Custom detectors that use various point-cloud based features to predict object attributes (one example is [5])
Please see the vision_msgs_examples repository for some sample vision
pipelines that emit results using the vision_msgs format.
RVIZ Plugins
The second package enables the visualisation of different detectors in RVIZ2. For more information about the capabilities, please see the README file.
References
- [1] YOLO
- [2] TensorFlow MNIST
- [3] LINEMOD
- [4] Object Recognition Kitchen
- [5] Attribute Detector
File truncated at 100 lines see the full file
CONTRIBUTING
Contributions to this repository are welcome. Please open a pull request to submit a contribution.
If you have questions about what types of messages would be considered in scope for this project, please create a GitHub issue to discuss your idea.
Any contribution that you make to this repository will be under the Apache 2 License, as dictated by that license:
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
Repository Summary
| Checkout URI | https://github.com/Kukanani/vision_msgs.git |
| VCS Type | git |
| VCS Version | ros2 |
| Last Updated | 2026-01-14 |
| Dev Status | MAINTAINED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| vision_msgs | 4.2.0 |
| vision_msgs_rviz_plugins | 4.2.0 |
README
ROS Vision Messages
Introduction
This package defines a set of messages to unify computer vision and object detection efforts in ROS.
Overview
The messages in this package are to define a common outward-facing interface for vision-based pipelines. The set of messages here are meant to enable 2 primary types of pipelines:
- “Pure” Classifiers, which identify class probabilities given a single sensor input
- Detectors, which identify class probabilities as well as the poses of those classes given a sensor input
The class probabilities are stored with an array of ObjectHypothesis messages, which is essentially a map from integer IDs to float scores and poses.
Message types exist separately for 2D and 3D. The metadata that is stored for each object is application-specific, and so this package places very few constraints on the metadata. Each possible detection result must have a unique numerical ID so that it can be unambiguously and efficiently identified in the results messages. Object metadata such as name, mesh, etc. can then be looked up from a database.
The only other requirement is that the metadata database information can be stored in a ROS parameter. We expect a classifier to load the database (or detailed database connection information) to the parameter server in a manner similar to how URDFs are loaded and stored there (see [6]), most likely defined in an XML format. This expectation may be further refined in the future using a ROS Enhancement Proposal, or REP [7].
We also would like classifiers to have a way to signal when the database has been updated, so that listeners can respond accordingly. The database might be updated in the case of online learning. To solve this problem, each classifier can publish messages to a topic signaling that the database has been updated, as well as incrementing a database version that’s continually published with the classifier information.
Source data that generated a classification or detection are not a part of the messages. If you need to access them, use an exact or approximate time synchronizer in your code, as the message’s header should match the header of the source data.
Semantic segmentation pipelines should use sensor_msgs/Image messages for publishing segmentation and confidence masks. This allows systems to use standard ROS tools for image processing, and allows choosing the most compact image encoding appropriate for the task. To transmit the metadata associated with the vision pipeline, you should use the /vision_msgs/LabelInfo message. This message works the same as /sensor_msgs/CameraInfo or /vision_msgs/VisionInfo:
-
Publish
LabelInfoto a topic. The topic should be at same namespace level as the associated image. That is, if your image is published at/my_segmentation_node/image, theLabelInfoshould be published at/my_segmentation_node/label_info. Use a latched publisher forLabelInfo, so that new nodes joining the ROS system can get the messages that were published since the beginning. In ROS2, this can be achieved using atransient localQoS profile. -
The subscribing node can get and store one
LabelInfomessage and cancel its subscription after that. This assumes the provider of the message publishes it periodically.
Messages
- Classification: pure classification without pose
- Detection2D and Detection3D: classification + pose
- BoundingBox2D, BoundingBox3D: orientable rectangular bounding boxes, specified by the pose of their center and their size.
- XArray messages, where X is one of the message types listed above. A pipeline should emit XArray messages as its forward-facing ROS interface.
- VisionInfo: Information about a classifier, such as its name and where to find its metadata database.
- ObjectHypothesis: An class_id/score pair.
- ObjectHypothesisWithPose: An ObjectHypothesis/pose pair. This accounts for the fact that a single input, say, a point cloud, could have different poses depdending on its class. For example, a flat rectangular prism could either be a smartphone lying on its back, or a book lying on its side.
By using a very general message definition, we hope to cover as many of the various computer vision use cases as possible. Some examples of use cases that can be fully represented are:
- Bounding box multi-object detectors with tight bounding box predictions, such as YOLO [1]
- Class-predicting full-image detectors, such as TensorFlow examples trained on the MNIST dataset [2]
- Full 6D-pose recognition pipelines, such as LINEMOD [3] and those included in the Object Recognition Kitchen [4]
- Custom detectors that use various point-cloud based features to predict object attributes (one example is [5])
Please see the vision_msgs_examples repository for some sample vision
pipelines that emit results using the vision_msgs format.
RVIZ Plugins
The second package enables the visualisation of different detectors in RVIZ2. For more information about the capabilities, please see the README file.
References
- [1] YOLO
- [2] TensorFlow MNIST
- [3] LINEMOD
- [4] Object Recognition Kitchen
- [5] Attribute Detector
File truncated at 100 lines see the full file
CONTRIBUTING
Contributions to this repository are welcome. Please open a pull request to submit a contribution.
If you have questions about what types of messages would be considered in scope for this project, please create a GitHub issue to discuss your idea.
Any contribution that you make to this repository will be under the Apache 2 License, as dictated by that license:
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
Repository Summary
| Checkout URI | https://github.com/ros-perception/vision_msgs.git |
| VCS Type | git |
| VCS Version | galactic |
| Last Updated | 2023-07-26 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| vision_msgs | 3.0.2 |
| vision_msgs_rviz_plugins | 4.1.0 |
README
ROS Vision Messages
Introduction
This package defines a set of messages to unify computer vision and object detection efforts in ROS.
Overview
The messages in this package are to define a common outward-facing interface for vision-based pipelines. The set of messages here are meant to enable 2 primary types of pipelines:
- “Pure” Classifiers, which identify class probabilities given a single sensor input
- Detectors, which identify class probabilities as well as the poses of those classes given a sensor input
The class probabilities are stored with an array of ObjectHypothesis messages, which is essentially a map from integer IDs to float scores and poses.
Message types exist separately for 2D and 3D. The metadata that is stored for each object is application-specific, and so this package places very few constraints on the metadata. Each possible detection result must have a unique numerical ID so that it can be unambiguously and efficiently identified in the results messages. Object metadata such as name, mesh, etc. can then be looked up from a database.
The only other requirement is that the metadata database information can be stored in a ROS parameter. We expect a classifier to load the database (or detailed database connection information) to the parameter server in a manner similar to how URDFs are loaded and stored there (see [6]), most likely defined in an XML format. This expectation may be further refined in the future using a ROS Enhancement Proposal, or REP [7].
We also would like classifiers to have a way to signal when the database has been updated, so that listeners can respond accordingly. The database might be updated in the case of online learning. To solve this problem, each classifier can publish messages to a topic signaling that the database has been updated, as well as incrementing a database version that’s continually published with the classifier information.
Source data that generated a classification or detection are not a part of the messages. If you need to access them, use an exact or approximate time synchronizer in your code, as the message’s header should match the header of the source data.
Messages
- Classification: pure classification without pose
- Detection2D and Detection3D: classification + pose
- XArray messages, where X is one of the two message types listed above. A pipeline should emit XArray messages as its forward-facing ROS interface.
- VisionInfo: Information about a classifier, such as its name and where to find its metadata database.
- ObjectHypothesis: An class_id/score pair.
- ObjectHypothesisWithPose: An ObjectHypothesis/pose pair. This accounts for the fact that a single input, say, a point cloud, could have different poses depdending on its class. For example, a flat rectangular prism could either be a smartphone lying on its back, or a book lying on its side.
- BoundingBox2D, BoundingBox3D: orientable rectangular bounding boxes, specified by the pose of their center and their size.
By using a very general message definition, we hope to cover as many of the various computer vision use cases as possible. Some examples of use cases that can be fully represented are:
- Bounding box multi-object detectors with tight bounding box predictions, such as YOLO [1]
- Class-predicting full-image detectors, such as TensorFlow examples trained on the MNIST dataset [2]
- Full 6D-pose recognition pipelines, such as LINEMOD [3] and those included in the Object Recognition Kitchen [4]
- Custom detectors that use various point-cloud based features to predict object attributes (one example is [5])
Please see the vision_msgs_examples repository for some sample vision
pipelines that emit results using the vision_msgs format.
References
- [1] YOLO
- [2] TensorFlow MNIST
- [3] LINEMOD
- [4] Object Recognition Kitchen
- [5] Attribute Detector
- [6] URDFs on the parameter server
- [7] ROS Enhancement Proposals
CONTRIBUTING
Contributions to this repository are welcome. Please open a pull request to submit a contribution.
If you have questions about what types of messages would be considered in scope for this project, please create a GitHub issue to discuss your idea.
Any contribution that you make to this repository will be under the Apache 2 License, as dictated by that license:
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
Repository Summary
| Checkout URI | https://github.com/Kukanani/vision_msgs.git |
| VCS Type | git |
| VCS Version | ros2 |
| Last Updated | 2026-01-14 |
| Dev Status | MAINTAINED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| vision_msgs | 4.2.0 |
| vision_msgs_rviz_plugins | 4.2.0 |
README
ROS Vision Messages
Introduction
This package defines a set of messages to unify computer vision and object detection efforts in ROS.
Overview
The messages in this package are to define a common outward-facing interface for vision-based pipelines. The set of messages here are meant to enable 2 primary types of pipelines:
- “Pure” Classifiers, which identify class probabilities given a single sensor input
- Detectors, which identify class probabilities as well as the poses of those classes given a sensor input
The class probabilities are stored with an array of ObjectHypothesis messages, which is essentially a map from integer IDs to float scores and poses.
Message types exist separately for 2D and 3D. The metadata that is stored for each object is application-specific, and so this package places very few constraints on the metadata. Each possible detection result must have a unique numerical ID so that it can be unambiguously and efficiently identified in the results messages. Object metadata such as name, mesh, etc. can then be looked up from a database.
The only other requirement is that the metadata database information can be stored in a ROS parameter. We expect a classifier to load the database (or detailed database connection information) to the parameter server in a manner similar to how URDFs are loaded and stored there (see [6]), most likely defined in an XML format. This expectation may be further refined in the future using a ROS Enhancement Proposal, or REP [7].
We also would like classifiers to have a way to signal when the database has been updated, so that listeners can respond accordingly. The database might be updated in the case of online learning. To solve this problem, each classifier can publish messages to a topic signaling that the database has been updated, as well as incrementing a database version that’s continually published with the classifier information.
Source data that generated a classification or detection are not a part of the messages. If you need to access them, use an exact or approximate time synchronizer in your code, as the message’s header should match the header of the source data.
Semantic segmentation pipelines should use sensor_msgs/Image messages for publishing segmentation and confidence masks. This allows systems to use standard ROS tools for image processing, and allows choosing the most compact image encoding appropriate for the task. To transmit the metadata associated with the vision pipeline, you should use the /vision_msgs/LabelInfo message. This message works the same as /sensor_msgs/CameraInfo or /vision_msgs/VisionInfo:
-
Publish
LabelInfoto a topic. The topic should be at same namespace level as the associated image. That is, if your image is published at/my_segmentation_node/image, theLabelInfoshould be published at/my_segmentation_node/label_info. Use a latched publisher forLabelInfo, so that new nodes joining the ROS system can get the messages that were published since the beginning. In ROS2, this can be achieved using atransient localQoS profile. -
The subscribing node can get and store one
LabelInfomessage and cancel its subscription after that. This assumes the provider of the message publishes it periodically.
Messages
- Classification: pure classification without pose
- Detection2D and Detection3D: classification + pose
- BoundingBox2D, BoundingBox3D: orientable rectangular bounding boxes, specified by the pose of their center and their size.
- XArray messages, where X is one of the message types listed above. A pipeline should emit XArray messages as its forward-facing ROS interface.
- VisionInfo: Information about a classifier, such as its name and where to find its metadata database.
- ObjectHypothesis: An class_id/score pair.
- ObjectHypothesisWithPose: An ObjectHypothesis/pose pair. This accounts for the fact that a single input, say, a point cloud, could have different poses depdending on its class. For example, a flat rectangular prism could either be a smartphone lying on its back, or a book lying on its side.
By using a very general message definition, we hope to cover as many of the various computer vision use cases as possible. Some examples of use cases that can be fully represented are:
- Bounding box multi-object detectors with tight bounding box predictions, such as YOLO [1]
- Class-predicting full-image detectors, such as TensorFlow examples trained on the MNIST dataset [2]
- Full 6D-pose recognition pipelines, such as LINEMOD [3] and those included in the Object Recognition Kitchen [4]
- Custom detectors that use various point-cloud based features to predict object attributes (one example is [5])
Please see the vision_msgs_examples repository for some sample vision
pipelines that emit results using the vision_msgs format.
RVIZ Plugins
The second package enables the visualisation of different detectors in RVIZ2. For more information about the capabilities, please see the README file.
References
- [1] YOLO
- [2] TensorFlow MNIST
- [3] LINEMOD
- [4] Object Recognition Kitchen
- [5] Attribute Detector
File truncated at 100 lines see the full file
CONTRIBUTING
Contributions to this repository are welcome. Please open a pull request to submit a contribution.
If you have questions about what types of messages would be considered in scope for this project, please create a GitHub issue to discuss your idea.
Any contribution that you make to this repository will be under the Apache 2 License, as dictated by that license:
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
Repository Summary
| Checkout URI | https://github.com/ros-perception/vision_msgs.git |
| VCS Type | git |
| VCS Version | ros2 |
| Last Updated | 2026-01-14 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| vision_msgs | 4.2.0 |
| vision_msgs_rviz_plugins | 4.2.0 |
README
ROS Vision Messages
Introduction
This package defines a set of messages to unify computer vision and object detection efforts in ROS.
Overview
The messages in this package are to define a common outward-facing interface for vision-based pipelines. The set of messages here are meant to enable 2 primary types of pipelines:
- “Pure” Classifiers, which identify class probabilities given a single sensor input
- Detectors, which identify class probabilities as well as the poses of those classes given a sensor input
The class probabilities are stored with an array of ObjectHypothesis messages, which is essentially a map from integer IDs to float scores and poses.
Message types exist separately for 2D and 3D. The metadata that is stored for each object is application-specific, and so this package places very few constraints on the metadata. Each possible detection result must have a unique numerical ID so that it can be unambiguously and efficiently identified in the results messages. Object metadata such as name, mesh, etc. can then be looked up from a database.
The only other requirement is that the metadata database information can be stored in a ROS parameter. We expect a classifier to load the database (or detailed database connection information) to the parameter server in a manner similar to how URDFs are loaded and stored there (see [6]), most likely defined in an XML format. This expectation may be further refined in the future using a ROS Enhancement Proposal, or REP [7].
We also would like classifiers to have a way to signal when the database has been updated, so that listeners can respond accordingly. The database might be updated in the case of online learning. To solve this problem, each classifier can publish messages to a topic signaling that the database has been updated, as well as incrementing a database version that’s continually published with the classifier information.
Source data that generated a classification or detection are not a part of the messages. If you need to access them, use an exact or approximate time synchronizer in your code, as the message’s header should match the header of the source data.
Semantic segmentation pipelines should use sensor_msgs/Image messages for publishing segmentation and confidence masks. This allows systems to use standard ROS tools for image processing, and allows choosing the most compact image encoding appropriate for the task. To transmit the metadata associated with the vision pipeline, you should use the /vision_msgs/LabelInfo message. This message works the same as /sensor_msgs/CameraInfo or /vision_msgs/VisionInfo:
-
Publish
LabelInfoto a topic. The topic should be at same namespace level as the associated image. That is, if your image is published at/my_segmentation_node/image, theLabelInfoshould be published at/my_segmentation_node/label_info. Use a latched publisher forLabelInfo, so that new nodes joining the ROS system can get the messages that were published since the beginning. In ROS2, this can be achieved using atransient localQoS profile. -
The subscribing node can get and store one
LabelInfomessage and cancel its subscription after that. This assumes the provider of the message publishes it periodically.
Messages
- Classification: pure classification without pose
- Detection2D and Detection3D: classification + pose
- BoundingBox2D, BoundingBox3D: orientable rectangular bounding boxes, specified by the pose of their center and their size.
- XArray messages, where X is one of the message types listed above. A pipeline should emit XArray messages as its forward-facing ROS interface.
- VisionInfo: Information about a classifier, such as its name and where to find its metadata database.
- ObjectHypothesis: An class_id/score pair.
- ObjectHypothesisWithPose: An ObjectHypothesis/pose pair. This accounts for the fact that a single input, say, a point cloud, could have different poses depdending on its class. For example, a flat rectangular prism could either be a smartphone lying on its back, or a book lying on its side.
By using a very general message definition, we hope to cover as many of the various computer vision use cases as possible. Some examples of use cases that can be fully represented are:
- Bounding box multi-object detectors with tight bounding box predictions, such as YOLO [1]
- Class-predicting full-image detectors, such as TensorFlow examples trained on the MNIST dataset [2]
- Full 6D-pose recognition pipelines, such as LINEMOD [3] and those included in the Object Recognition Kitchen [4]
- Custom detectors that use various point-cloud based features to predict object attributes (one example is [5])
Please see the vision_msgs_examples repository for some sample vision
pipelines that emit results using the vision_msgs format.
RVIZ Plugins
The second package enables the visualisation of different detectors in RVIZ2. For more information about the capabilities, please see the README file.
References
- [1] YOLO
- [2] TensorFlow MNIST
- [3] LINEMOD
- [4] Object Recognition Kitchen
- [5] Attribute Detector
File truncated at 100 lines see the full file
CONTRIBUTING
Contributions to this repository are welcome. Please open a pull request to submit a contribution.
If you have questions about what types of messages would be considered in scope for this project, please create a GitHub issue to discuss your idea.
Any contribution that you make to this repository will be under the Apache 2 License, as dictated by that license:
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
Repository Summary
| Checkout URI | https://github.com/Kukanani/vision_msgs.git |
| VCS Type | git |
| VCS Version | lunar-devel |
| Last Updated | 2017-11-14 |
| Dev Status | MAINTAINED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| vision_msgs | 0.0.1 |
README
ROS Vision Messages
Introduction
This package defines a set of messages to unify computer vision and object detection efforts in ROS.
Overview
The messages in this package are to define a common outward-facing interface for vision-based pipelines. The set of messages here are meant to enable 2 primary types of pipelines:
- “Pure” Classifiers, which identify class probabilities given a single sensor input
- Detectors, which identify class probabilities as well as the poses of those classes given a sensor input
The class probabilities are stored with an array of ObjectHypothesis messages, which is essentially a map from integer IDs to float scores and poses.
Message types exist separately for 2D (using sensor_msgs/Image) and 3D (using
sensor_msgs\PointCloud2). The metadata that is stored for each object is
application-specific, and so this package places very few constraints on the
metadata. Each possible detection result must have a unique numerical ID so
that it can be unambiguously and efficiently identified in the results messages.
Object metadata such as name, mesh, etc. can then be looked up from a database.
The only other requirement is that the metadata database information can be stored in a ROS parameter. We expect a classifier to load the database (or detailed database connection information) to the parameter server in a manner similar to how URDFs are loaded and stored there (see [6]), most likely defined in an XML format. This expectation may be further refined in the future using a ROS Enhancement Proposal, or REP [7].
We also would like classifiers to have a way to signal when the database has been updated, so that listeners can respond accordingly. The database might be updated in the case of online learning. To solve this problem, each classifier can publish messages to a topic signaling that the database has been updated, as well as incrementing a database version that’s continually published with the classifier information.
Messages
- Classification2D and Classification3D: pure classification without pose
- Detection2D and Detection3D: classification + pose
- XArray messages, where X is one of the four message types listed above. A pipeline should emit XArray messages as its forward-facing ROS interface.
- VisionInfo: Information about a classifier, such as its name and where to find its metadata database.
- ObjectHypothesis: An id/score pair.
- ObjectHypothesisWithPose: An id/(score, pose) pair. This accounts for the fact that a single input, say, a point cloud, could have different poses depdending on its class. For example, a flat rectangular prism could either be a smartphone lying on its back, or a book lying on its side.
- BoundingBox2D, BoundingBox3D: orientable rectangular bounding boxes, specified by the pose of their center and their size.
By using a very general message definition, we hope to cover as many of the various computer vision use cases as possible. Some examples of use cases that can be fully represented are:
- Bounding box multi-object detectors with tight bounding box predictions, such as YOLO [1]
- Class-predicting full-image detectors, such as TensorFlow examples trained on the MNIST dataset [2]
- Full 6D-pose recognition pipelines, such as LINEMOD [3] and those included in the Object Recognition Kitchen [4]
- Custom detectors that use various point-cloud based features to predict object attributes (one example is [5])
Please see the vision_msgs_examples repository for some sample vision
pipelines that emit results using the vision_msgs format.
References
- [1] YOLO
- [2] TensorFlow MNIST
- [3] LINEMOD
- [4] Object Recognition Kitchen
- [5] Attribute Detector
- [6] URDFs on the parameter server
- [7] ROS Enhancement Proposals
CONTRIBUTING
Repository Summary
| Checkout URI | https://github.com/ros-perception/vision_msgs.git |
| VCS Type | git |
| VCS Version | ros2 |
| Last Updated | 2026-01-14 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| vision_msgs | 4.2.0 |
| vision_msgs_rviz_plugins | 4.2.0 |
README
ROS Vision Messages
Introduction
This package defines a set of messages to unify computer vision and object detection efforts in ROS.
Overview
The messages in this package are to define a common outward-facing interface for vision-based pipelines. The set of messages here are meant to enable 2 primary types of pipelines:
- “Pure” Classifiers, which identify class probabilities given a single sensor input
- Detectors, which identify class probabilities as well as the poses of those classes given a sensor input
The class probabilities are stored with an array of ObjectHypothesis messages, which is essentially a map from integer IDs to float scores and poses.
Message types exist separately for 2D and 3D. The metadata that is stored for each object is application-specific, and so this package places very few constraints on the metadata. Each possible detection result must have a unique numerical ID so that it can be unambiguously and efficiently identified in the results messages. Object metadata such as name, mesh, etc. can then be looked up from a database.
The only other requirement is that the metadata database information can be stored in a ROS parameter. We expect a classifier to load the database (or detailed database connection information) to the parameter server in a manner similar to how URDFs are loaded and stored there (see [6]), most likely defined in an XML format. This expectation may be further refined in the future using a ROS Enhancement Proposal, or REP [7].
We also would like classifiers to have a way to signal when the database has been updated, so that listeners can respond accordingly. The database might be updated in the case of online learning. To solve this problem, each classifier can publish messages to a topic signaling that the database has been updated, as well as incrementing a database version that’s continually published with the classifier information.
Source data that generated a classification or detection are not a part of the messages. If you need to access them, use an exact or approximate time synchronizer in your code, as the message’s header should match the header of the source data.
Semantic segmentation pipelines should use sensor_msgs/Image messages for publishing segmentation and confidence masks. This allows systems to use standard ROS tools for image processing, and allows choosing the most compact image encoding appropriate for the task. To transmit the metadata associated with the vision pipeline, you should use the /vision_msgs/LabelInfo message. This message works the same as /sensor_msgs/CameraInfo or /vision_msgs/VisionInfo:
-
Publish
LabelInfoto a topic. The topic should be at same namespace level as the associated image. That is, if your image is published at/my_segmentation_node/image, theLabelInfoshould be published at/my_segmentation_node/label_info. Use a latched publisher forLabelInfo, so that new nodes joining the ROS system can get the messages that were published since the beginning. In ROS2, this can be achieved using atransient localQoS profile. -
The subscribing node can get and store one
LabelInfomessage and cancel its subscription after that. This assumes the provider of the message publishes it periodically.
Messages
- Classification: pure classification without pose
- Detection2D and Detection3D: classification + pose
- BoundingBox2D, BoundingBox3D: orientable rectangular bounding boxes, specified by the pose of their center and their size.
- XArray messages, where X is one of the message types listed above. A pipeline should emit XArray messages as its forward-facing ROS interface.
- VisionInfo: Information about a classifier, such as its name and where to find its metadata database.
- ObjectHypothesis: An class_id/score pair.
- ObjectHypothesisWithPose: An ObjectHypothesis/pose pair. This accounts for the fact that a single input, say, a point cloud, could have different poses depdending on its class. For example, a flat rectangular prism could either be a smartphone lying on its back, or a book lying on its side.
By using a very general message definition, we hope to cover as many of the various computer vision use cases as possible. Some examples of use cases that can be fully represented are:
- Bounding box multi-object detectors with tight bounding box predictions, such as YOLO [1]
- Class-predicting full-image detectors, such as TensorFlow examples trained on the MNIST dataset [2]
- Full 6D-pose recognition pipelines, such as LINEMOD [3] and those included in the Object Recognition Kitchen [4]
- Custom detectors that use various point-cloud based features to predict object attributes (one example is [5])
Please see the vision_msgs_examples repository for some sample vision
pipelines that emit results using the vision_msgs format.
RVIZ Plugins
The second package enables the visualisation of different detectors in RVIZ2. For more information about the capabilities, please see the README file.
References
- [1] YOLO
- [2] TensorFlow MNIST
- [3] LINEMOD
- [4] Object Recognition Kitchen
- [5] Attribute Detector
File truncated at 100 lines see the full file
CONTRIBUTING
Contributions to this repository are welcome. Please open a pull request to submit a contribution.
If you have questions about what types of messages would be considered in scope for this project, please create a GitHub issue to discuss your idea.
Any contribution that you make to this repository will be under the Apache 2 License, as dictated by that license:
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
Repository Summary
| Checkout URI | https://github.com/ros-perception/vision_msgs.git |
| VCS Type | git |
| VCS Version | ros2 |
| Last Updated | 2026-01-14 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| vision_msgs | 4.2.0 |
| vision_msgs_rviz_plugins | 4.2.0 |
README
ROS Vision Messages
Introduction
This package defines a set of messages to unify computer vision and object detection efforts in ROS.
Overview
The messages in this package are to define a common outward-facing interface for vision-based pipelines. The set of messages here are meant to enable 2 primary types of pipelines:
- “Pure” Classifiers, which identify class probabilities given a single sensor input
- Detectors, which identify class probabilities as well as the poses of those classes given a sensor input
The class probabilities are stored with an array of ObjectHypothesis messages, which is essentially a map from integer IDs to float scores and poses.
Message types exist separately for 2D and 3D. The metadata that is stored for each object is application-specific, and so this package places very few constraints on the metadata. Each possible detection result must have a unique numerical ID so that it can be unambiguously and efficiently identified in the results messages. Object metadata such as name, mesh, etc. can then be looked up from a database.
The only other requirement is that the metadata database information can be stored in a ROS parameter. We expect a classifier to load the database (or detailed database connection information) to the parameter server in a manner similar to how URDFs are loaded and stored there (see [6]), most likely defined in an XML format. This expectation may be further refined in the future using a ROS Enhancement Proposal, or REP [7].
We also would like classifiers to have a way to signal when the database has been updated, so that listeners can respond accordingly. The database might be updated in the case of online learning. To solve this problem, each classifier can publish messages to a topic signaling that the database has been updated, as well as incrementing a database version that’s continually published with the classifier information.
Source data that generated a classification or detection are not a part of the messages. If you need to access them, use an exact or approximate time synchronizer in your code, as the message’s header should match the header of the source data.
Semantic segmentation pipelines should use sensor_msgs/Image messages for publishing segmentation and confidence masks. This allows systems to use standard ROS tools for image processing, and allows choosing the most compact image encoding appropriate for the task. To transmit the metadata associated with the vision pipeline, you should use the /vision_msgs/LabelInfo message. This message works the same as /sensor_msgs/CameraInfo or /vision_msgs/VisionInfo:
-
Publish
LabelInfoto a topic. The topic should be at same namespace level as the associated image. That is, if your image is published at/my_segmentation_node/image, theLabelInfoshould be published at/my_segmentation_node/label_info. Use a latched publisher forLabelInfo, so that new nodes joining the ROS system can get the messages that were published since the beginning. In ROS2, this can be achieved using atransient localQoS profile. -
The subscribing node can get and store one
LabelInfomessage and cancel its subscription after that. This assumes the provider of the message publishes it periodically.
Messages
- Classification: pure classification without pose
- Detection2D and Detection3D: classification + pose
- BoundingBox2D, BoundingBox3D: orientable rectangular bounding boxes, specified by the pose of their center and their size.
- XArray messages, where X is one of the message types listed above. A pipeline should emit XArray messages as its forward-facing ROS interface.
- VisionInfo: Information about a classifier, such as its name and where to find its metadata database.
- ObjectHypothesis: An class_id/score pair.
- ObjectHypothesisWithPose: An ObjectHypothesis/pose pair. This accounts for the fact that a single input, say, a point cloud, could have different poses depdending on its class. For example, a flat rectangular prism could either be a smartphone lying on its back, or a book lying on its side.
By using a very general message definition, we hope to cover as many of the various computer vision use cases as possible. Some examples of use cases that can be fully represented are:
- Bounding box multi-object detectors with tight bounding box predictions, such as YOLO [1]
- Class-predicting full-image detectors, such as TensorFlow examples trained on the MNIST dataset [2]
- Full 6D-pose recognition pipelines, such as LINEMOD [3] and those included in the Object Recognition Kitchen [4]
- Custom detectors that use various point-cloud based features to predict object attributes (one example is [5])
Please see the vision_msgs_examples repository for some sample vision
pipelines that emit results using the vision_msgs format.
RVIZ Plugins
The second package enables the visualisation of different detectors in RVIZ2. For more information about the capabilities, please see the README file.
References
- [1] YOLO
- [2] TensorFlow MNIST
- [3] LINEMOD
- [4] Object Recognition Kitchen
- [5] Attribute Detector
File truncated at 100 lines see the full file
CONTRIBUTING
Contributions to this repository are welcome. Please open a pull request to submit a contribution.
If you have questions about what types of messages would be considered in scope for this project, please create a GitHub issue to discuss your idea.
Any contribution that you make to this repository will be under the Apache 2 License, as dictated by that license:
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
Repository Summary
| Checkout URI | https://github.com/ros-perception/vision_msgs.git |
| VCS Type | git |
| VCS Version | ros2 |
| Last Updated | 2026-01-14 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| vision_msgs | 4.2.0 |
| vision_msgs_rviz_plugins | 4.2.0 |
README
ROS Vision Messages
Introduction
This package defines a set of messages to unify computer vision and object detection efforts in ROS.
Overview
The messages in this package are to define a common outward-facing interface for vision-based pipelines. The set of messages here are meant to enable 2 primary types of pipelines:
- “Pure” Classifiers, which identify class probabilities given a single sensor input
- Detectors, which identify class probabilities as well as the poses of those classes given a sensor input
The class probabilities are stored with an array of ObjectHypothesis messages, which is essentially a map from integer IDs to float scores and poses.
Message types exist separately for 2D and 3D. The metadata that is stored for each object is application-specific, and so this package places very few constraints on the metadata. Each possible detection result must have a unique numerical ID so that it can be unambiguously and efficiently identified in the results messages. Object metadata such as name, mesh, etc. can then be looked up from a database.
The only other requirement is that the metadata database information can be stored in a ROS parameter. We expect a classifier to load the database (or detailed database connection information) to the parameter server in a manner similar to how URDFs are loaded and stored there (see [6]), most likely defined in an XML format. This expectation may be further refined in the future using a ROS Enhancement Proposal, or REP [7].
We also would like classifiers to have a way to signal when the database has been updated, so that listeners can respond accordingly. The database might be updated in the case of online learning. To solve this problem, each classifier can publish messages to a topic signaling that the database has been updated, as well as incrementing a database version that’s continually published with the classifier information.
Source data that generated a classification or detection are not a part of the messages. If you need to access them, use an exact or approximate time synchronizer in your code, as the message’s header should match the header of the source data.
Semantic segmentation pipelines should use sensor_msgs/Image messages for publishing segmentation and confidence masks. This allows systems to use standard ROS tools for image processing, and allows choosing the most compact image encoding appropriate for the task. To transmit the metadata associated with the vision pipeline, you should use the /vision_msgs/LabelInfo message. This message works the same as /sensor_msgs/CameraInfo or /vision_msgs/VisionInfo:
-
Publish
LabelInfoto a topic. The topic should be at same namespace level as the associated image. That is, if your image is published at/my_segmentation_node/image, theLabelInfoshould be published at/my_segmentation_node/label_info. Use a latched publisher forLabelInfo, so that new nodes joining the ROS system can get the messages that were published since the beginning. In ROS2, this can be achieved using atransient localQoS profile. -
The subscribing node can get and store one
LabelInfomessage and cancel its subscription after that. This assumes the provider of the message publishes it periodically.
Messages
- Classification: pure classification without pose
- Detection2D and Detection3D: classification + pose
- BoundingBox2D, BoundingBox3D: orientable rectangular bounding boxes, specified by the pose of their center and their size.
- XArray messages, where X is one of the message types listed above. A pipeline should emit XArray messages as its forward-facing ROS interface.
- VisionInfo: Information about a classifier, such as its name and where to find its metadata database.
- ObjectHypothesis: An class_id/score pair.
- ObjectHypothesisWithPose: An ObjectHypothesis/pose pair. This accounts for the fact that a single input, say, a point cloud, could have different poses depdending on its class. For example, a flat rectangular prism could either be a smartphone lying on its back, or a book lying on its side.
By using a very general message definition, we hope to cover as many of the various computer vision use cases as possible. Some examples of use cases that can be fully represented are:
- Bounding box multi-object detectors with tight bounding box predictions, such as YOLO [1]
- Class-predicting full-image detectors, such as TensorFlow examples trained on the MNIST dataset [2]
- Full 6D-pose recognition pipelines, such as LINEMOD [3] and those included in the Object Recognition Kitchen [4]
- Custom detectors that use various point-cloud based features to predict object attributes (one example is [5])
Please see the vision_msgs_examples repository for some sample vision
pipelines that emit results using the vision_msgs format.
RVIZ Plugins
The second package enables the visualisation of different detectors in RVIZ2. For more information about the capabilities, please see the README file.
References
- [1] YOLO
- [2] TensorFlow MNIST
- [3] LINEMOD
- [4] Object Recognition Kitchen
- [5] Attribute Detector
File truncated at 100 lines see the full file
CONTRIBUTING
Contributions to this repository are welcome. Please open a pull request to submit a contribution.
If you have questions about what types of messages would be considered in scope for this project, please create a GitHub issue to discuss your idea.
Any contribution that you make to this repository will be under the Apache 2 License, as dictated by that license:
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
Repository Summary
| Checkout URI | https://github.com/Kukanani/vision_msgs.git |
| VCS Type | git |
| VCS Version | kinetic-devel |
| Last Updated | 2020-12-09 |
| Dev Status | MAINTAINED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| vision_msgs | 0.0.1 |
README
ROS Vision Messages
Introduction
This package defines a set of messages to unify computer vision and object detection efforts in ROS.
Overview
The messages in this package are to define a common outward-facing interface for vision-based pipelines. The set of messages here are meant to enable 2 primary types of pipelines:
- “Pure” Classifiers, which identify class probabilities given a single sensor input
- Detectors, which identify class probabilities as well as the poses of those classes given a sensor input
The class probabilities are stored with an array of ObjectHypothesis messages, which is essentially a map from integer IDs to float scores and poses.
Message types exist separately for 2D (using sensor_msgs/Image) and 3D (using
sensor_msgs\PointCloud2). The metadata that is stored for each object is
application-specific, and so this package places very few constraints on the
metadata. Each possible detection result must have a unique numerical ID so
that it can be unambiguously and efficiently identified in the results messages.
Object metadata such as name, mesh, etc. can then be looked up from a database.
The only other requirement is that the metadata database information can be stored in a ROS parameter. We expect a classifier to load the database (or detailed database connection information) to the parameter server in a manner similar to how URDFs are loaded and stored there (see [6]), most likely defined in an XML format. This expectation may be further refined in the future using a ROS Enhancement Proposal, or REP [7].
We also would like classifiers to have a way to signal when the database has been updated, so that listeners can respond accordingly. The database might be updated in the case of online learning. To solve this problem, each classifier can publish messages to a topic signaling that the database has been updated, as well as incrementing a database version that’s continually published with the classifier information.
Messages
- Classification2D and Classification3D: pure classification without pose
- Detection2D and Detection3D: classification + pose
- XArray messages, where X is one of the four message types listed above. A pipeline should emit XArray messages as its forward-facing ROS interface.
- VisionInfo: Information about a classifier, such as its name and where to find its metadata database.
- ObjectHypothesis: An id/score pair.
- ObjectHypothesisWithPose: An id/(score, pose) pair. This accounts for the fact that a single input, say, a point cloud, could have different poses depdending on its class. For example, a flat rectangular prism could either be a smartphone lying on its back, or a book lying on its side.
- BoundingBox2D, BoundingBox3D: orientable rectangular bounding boxes, specified by the pose of their center and their size.
By using a very general message definition, we hope to cover as many of the various computer vision use cases as possible. Some examples of use cases that can be fully represented are:
- Bounding box multi-object detectors with tight bounding box predictions, such as YOLO [1]
- Class-predicting full-image detectors, such as TensorFlow examples trained on the MNIST dataset [2]
- Full 6D-pose recognition pipelines, such as LINEMOD [3] and those included in the Object Recognition Kitchen [4]
- Custom detectors that use various point-cloud based features to predict object attributes (one example is [5])
Please see the vision_msgs_examples repository for some sample vision
pipelines that emit results using the vision_msgs format.
References
- [1] YOLO
- [2] TensorFlow MNIST
- [3] LINEMOD
- [4] Object Recognition Kitchen
- [5] Attribute Detector
- [6] URDFs on the parameter server
- [7] ROS Enhancement Proposals
CONTRIBUTING
Repository Summary
| Checkout URI | https://github.com/Kukanani/vision_msgs.git |
| VCS Type | git |
| VCS Version | melodic-devel |
| Last Updated | 2017-11-14 |
| Dev Status | MAINTAINED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| vision_msgs | 0.0.1 |
README
ROS Vision Messages
Introduction
This package defines a set of messages to unify computer vision and object detection efforts in ROS.
Overview
The messages in this package are to define a common outward-facing interface for vision-based pipelines. The set of messages here are meant to enable 2 primary types of pipelines:
- “Pure” Classifiers, which identify class probabilities given a single sensor input
- Detectors, which identify class probabilities as well as the poses of those classes given a sensor input
The class probabilities are stored with an array of ObjectHypothesis messages, which is essentially a map from integer IDs to float scores and poses.
Message types exist separately for 2D (using sensor_msgs/Image) and 3D (using
sensor_msgs\PointCloud2). The metadata that is stored for each object is
application-specific, and so this package places very few constraints on the
metadata. Each possible detection result must have a unique numerical ID so
that it can be unambiguously and efficiently identified in the results messages.
Object metadata such as name, mesh, etc. can then be looked up from a database.
The only other requirement is that the metadata database information can be stored in a ROS parameter. We expect a classifier to load the database (or detailed database connection information) to the parameter server in a manner similar to how URDFs are loaded and stored there (see [6]), most likely defined in an XML format. This expectation may be further refined in the future using a ROS Enhancement Proposal, or REP [7].
We also would like classifiers to have a way to signal when the database has been updated, so that listeners can respond accordingly. The database might be updated in the case of online learning. To solve this problem, each classifier can publish messages to a topic signaling that the database has been updated, as well as incrementing a database version that’s continually published with the classifier information.
Messages
- Classification2D and Classification3D: pure classification without pose
- Detection2D and Detection3D: classification + pose
- XArray messages, where X is one of the four message types listed above. A pipeline should emit XArray messages as its forward-facing ROS interface.
- VisionInfo: Information about a classifier, such as its name and where to find its metadata database.
- ObjectHypothesis: An id/score pair.
- ObjectHypothesisWithPose: An id/(score, pose) pair. This accounts for the fact that a single input, say, a point cloud, could have different poses depdending on its class. For example, a flat rectangular prism could either be a smartphone lying on its back, or a book lying on its side.
- BoundingBox2D, BoundingBox3D: orientable rectangular bounding boxes, specified by the pose of their center and their size.
By using a very general message definition, we hope to cover as many of the various computer vision use cases as possible. Some examples of use cases that can be fully represented are:
- Bounding box multi-object detectors with tight bounding box predictions, such as YOLO [1]
- Class-predicting full-image detectors, such as TensorFlow examples trained on the MNIST dataset [2]
- Full 6D-pose recognition pipelines, such as LINEMOD [3] and those included in the Object Recognition Kitchen [4]
- Custom detectors that use various point-cloud based features to predict object attributes (one example is [5])
Please see the vision_msgs_examples repository for some sample vision
pipelines that emit results using the vision_msgs format.
References
- [1] YOLO
- [2] TensorFlow MNIST
- [3] LINEMOD
- [4] Object Recognition Kitchen
- [5] Attribute Detector
- [6] URDFs on the parameter server
- [7] ROS Enhancement Proposals
CONTRIBUTING
Repository Summary
| Checkout URI | https://github.com/Kukanani/vision_msgs.git |
| VCS Type | git |
| VCS Version | noetic-devel |
| Last Updated | 2022-04-09 |
| Dev Status | MAINTAINED |
| Released | RELEASED |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| vision_msgs | 0.0.2 |
README
ROS Vision Messages
Introduction
This package defines a set of messages to unify computer vision and object detection efforts in ROS.
Overview
The messages in this package are to define a common outward-facing interface for vision-based pipelines. The set of messages here are meant to enable 2 primary types of pipelines:
- “Pure” Classifiers, which identify class probabilities given a single sensor input
- Detectors, which identify class probabilities as well as the poses of those classes given a sensor input
The class probabilities are stored with an array of ObjectHypothesis messages, which is essentially a map from integer IDs to float scores and poses.
Message types exist separately for 2D (using sensor_msgs/Image) and 3D (using
sensor_msgs\PointCloud2). The metadata that is stored for each object is
application-specific, and so this package places very few constraints on the
metadata. Each possible detection result must have a unique numerical ID so
that it can be unambiguously and efficiently identified in the results messages.
Object metadata such as name, mesh, etc. can then be looked up from a database.
The only other requirement is that the metadata database information can be stored in a ROS parameter. We expect a classifier to load the database (or detailed database connection information) to the parameter server in a manner similar to how URDFs are loaded and stored there (see [6]), most likely defined in an XML format. This expectation may be further refined in the future using a ROS Enhancement Proposal, or REP [7].
We also would like classifiers to have a way to signal when the database has been updated, so that listeners can respond accordingly. The database might be updated in the case of online learning. To solve this problem, each classifier can publish messages to a topic signaling that the database has been updated, as well as incrementing a database version that’s continually published with the classifier information.
Messages
- Classification2D and Classification3D: pure classification without pose.
- BoundingBox2D, BoundingBox3D: orientable rectangular bounding boxes, specified by the pose of their center and their size.
- Detection2D and Detection3D: classification + pose.
- XArray messages, where X is one of the six message types listed above. A pipeline should emit XArray messages as its forward-facing ROS interface.
- VisionInfo: Information about a classifier, such as its name and where to find its metadata database.
- ObjectHypothesis: An id/score pair.
- ObjectHypothesisWithPose: An id/(score, pose) pair. This accounts for the fact that a single input, say, a point cloud, could have different poses depdending on its class. For example, a flat rectangular prism could either be a smartphone lying on its back, or a book lying on its side.
By using a very general message definition, we hope to cover as many of the various computer vision use cases as possible. Some examples of use cases that can be fully represented are:
- Bounding box multi-object detectors with tight bounding box predictions, such as YOLO [1]
- Class-predicting full-image detectors, such as TensorFlow examples trained on the MNIST dataset [2]
- Full 6D-pose recognition pipelines, such as LINEMOD [3] and those included in the Object Recognition Kitchen [4]
- Custom detectors that use various point-cloud based features to predict object attributes (one example is [5])
Please see the vision_msgs_examples repository for some sample vision
pipelines that emit results using the vision_msgs format.
References
- [1] YOLO
- [2] TensorFlow MNIST
- [3] LINEMOD
- [4] Object Recognition Kitchen
- [5] Attribute Detector
- [6] URDFs on the parameter server
- [7] ROS Enhancement Proposals