
Repository Summary
| Checkout URI | https://github.com/suurjaak/grepros.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2024-05-06 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Tags | No category tags. |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| grepros | 1.2.2 |
README
grepros
grep for ROS bag files and live topics: read, filter, export.
Searches through ROS messages and matches any message field value by regular expression patterns or plain text, regardless of field type. Can also look for specific values in specific message fields only.
By default, matches are printed to console. Additionally, matches can be written to a bagfile or HTML/CSV/MCAP/Parquet/Postgres/SQL/SQLite, or published to live topics.
Supports both ROS1 and ROS2. ROS environment variables need to be set, at least ROS_VERSION.
Supported bag formats: .bag (ROS1), .db3 (ROS2), .mcap (ROS1, ROS2).
In ROS1, messages can be grepped even if Python packages for message types are not installed. Using ROS1 live topics requires ROS master to be running.
Using ROS2 requires Python packages for message types to be available in path.
Supports loading custom plugins, mainly for additional output formats.
Usable as a Python library, see LIBRARY.md. Full API documentation available at https://suurjaak.github.io/grepros.
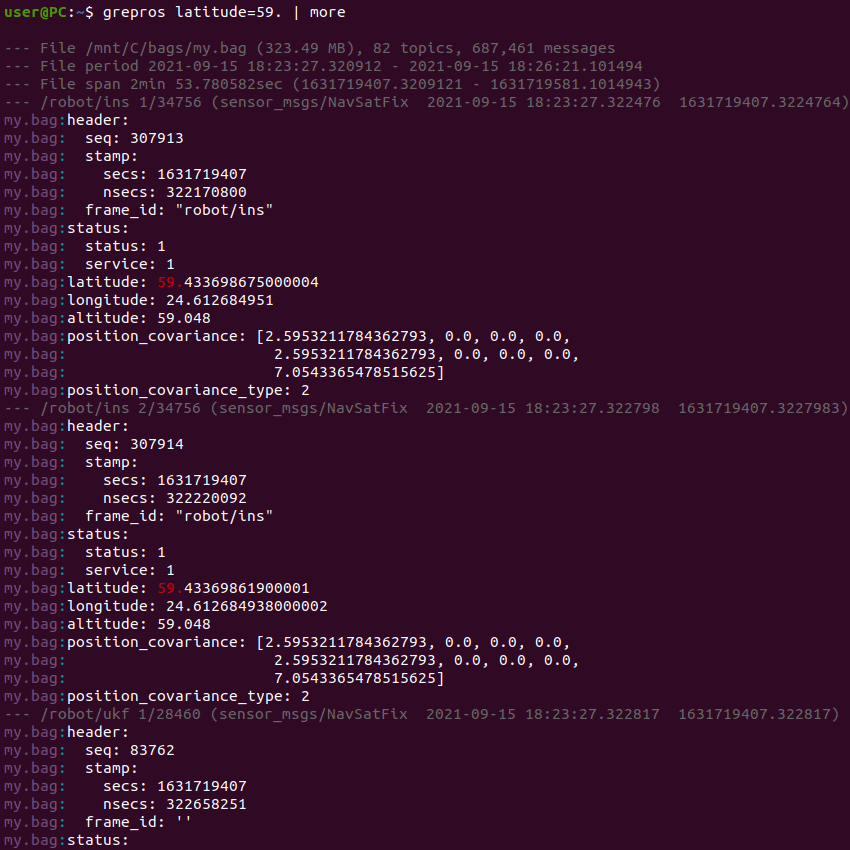
- Example usage
- Installation
- Inputs
- Outputs
- Matching and filtering
- Plugins
- Notes on ROS1 vs ROS2
- All command-line arguments
- Dependencies
- Attribution
- License
Example usage
Search for “my text” in all bags under current directory and subdirectories:
grepros -r "my text"
Print 30 lines of the first message from each live ROS topic:
grepros --max-per-topic 1 --lines-per-message 30 --live
Find first message containing “future” (case-sensitive) in my.bag:
grepros future -I --max-count 1 --name my.bag
Find 10 messages, from geometry_msgs package, in “map” frame, from bags in current directory, reindexing any unindexed bags:
grepros frame_id=map --type geometry_msgs/* --max-count 10 --reindex-if-unindexed
Pipe all diagnostics messages with “CPU usage” from live ROS topics to my.bag:
grepros "CPU usage" --type *DiagnosticArray --no-console-output --write my.bag
Find messages with field “key” containing “0xA002”, in topics ending with “diagnostics”, in bags under “/tmp”:
grepros key=0xA002 --topic *diagnostics --path /tmp
Find diagnostics_msgs messages in bags in current directory, containing “navigation” in fields “name” or “message”, print only header stamp and values:
grepros --type diagnostic_msgs/* --select-field name message \
--emit-field header.stamp status.values -- navigation
Print first message from each lidar topic on ROS1 host 1.2.3.4, without highlight:
ROS_MASTER_URI=http://1.2.3.4::11311 \
grepros --live --topic *lidar* --max-per-topic 1 --no-highlight
Export all bag messages to SQLite and Postgres, print only export progress:
grepros -n my.bag --write my.bag.sqlite --no-console-output --no-verbose --progress
grepros -n my.bag --write postgresql://user@host/dbname \
--no-console-output --no-verbose --progress
Patterns use Python regular expression syntax, message matches if all match. ‘*’ wildcards use simple globbing as zero or more characters, target matches if any value matches.
Note that some expressions may need to be quoted to avoid shell auto-unescaping
or auto-expanding them, e.g. linear.x=2.?5 should be given as "linear.x=2\.?5".
Care must also be taken with unquoted wildcards, as they will auto-expanded by shell if they happen to match paths on disk.
File truncated at 100 lines see the full file
CONTRIBUTING
Repository Summary
| Checkout URI | https://github.com/suurjaak/grepros.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2024-05-06 |
| Dev Status | DEVELOPED |
| Released | RELEASED |
| Tags | No category tags. |
| Contributing |
Help Wanted (-)
Good First Issues (-) Pull Requests to Review (-) |
Packages
| Name | Version |
|---|---|
| grepros | 1.2.2 |
README
grepros
grep for ROS bag files and live topics: read, filter, export.
Searches through ROS messages and matches any message field value by regular expression patterns or plain text, regardless of field type. Can also look for specific values in specific message fields only.
By default, matches are printed to console. Additionally, matches can be written to a bagfile or HTML/CSV/MCAP/Parquet/Postgres/SQL/SQLite, or published to live topics.
Supports both ROS1 and ROS2. ROS environment variables need to be set, at least ROS_VERSION.
Supported bag formats: .bag (ROS1), .db3 (ROS2), .mcap (ROS1, ROS2).
In ROS1, messages can be grepped even if Python packages for message types are not installed. Using ROS1 live topics requires ROS master to be running.
Using ROS2 requires Python packages for message types to be available in path.
Supports loading custom plugins, mainly for additional output formats.
Usable as a Python library, see LIBRARY.md. Full API documentation available at https://suurjaak.github.io/grepros.
- Example usage
- Installation
- Inputs
- Outputs
- Matching and filtering
- Plugins
- Notes on ROS1 vs ROS2
- All command-line arguments
- Dependencies
- Attribution
- License
Example usage
Search for “my text” in all bags under current directory and subdirectories:
grepros -r "my text"
Print 30 lines of the first message from each live ROS topic:
grepros --max-per-topic 1 --lines-per-message 30 --live
Find first message containing “future” (case-sensitive) in my.bag:
grepros future -I --max-count 1 --name my.bag
Find 10 messages, from geometry_msgs package, in “map” frame, from bags in current directory, reindexing any unindexed bags:
grepros frame_id=map --type geometry_msgs/* --max-count 10 --reindex-if-unindexed
Pipe all diagnostics messages with “CPU usage” from live ROS topics to my.bag:
grepros "CPU usage" --type *DiagnosticArray --no-console-output --write my.bag
Find messages with field “key” containing “0xA002”, in topics ending with “diagnostics”, in bags under “/tmp”:
grepros key=0xA002 --topic *diagnostics --path /tmp
Find diagnostics_msgs messages in bags in current directory, containing “navigation” in fields “name” or “message”, print only header stamp and values:
grepros --type diagnostic_msgs/* --select-field name message \
--emit-field header.stamp status.values -- navigation
Print first message from each lidar topic on ROS1 host 1.2.3.4, without highlight:
ROS_MASTER_URI=http://1.2.3.4::11311 \
grepros --live --topic *lidar* --max-per-topic 1 --no-highlight
Export all bag messages to SQLite and Postgres, print only export progress:
grepros -n my.bag --write my.bag.sqlite --no-console-output --no-verbose --progress
grepros -n my.bag --write postgresql://user@host/dbname \
--no-console-output --no-verbose --progress
Patterns use Python regular expression syntax, message matches if all match. ‘*’ wildcards use simple globbing as zero or more characters, target matches if any value matches.
Note that some expressions may need to be quoted to avoid shell auto-unescaping
or auto-expanding them, e.g. linear.x=2.?5 should be given as "linear.x=2\.?5".
Care must also be taken with unquoted wildcards, as they will auto-expanded by shell if they happen to match paths on disk.
File truncated at 100 lines see the full file